1.目前使用的是static的4 core节点集群测试
2.版本号:5.7.0,MQTT V3
3.测试工具:emqtt-bench
4.现象:
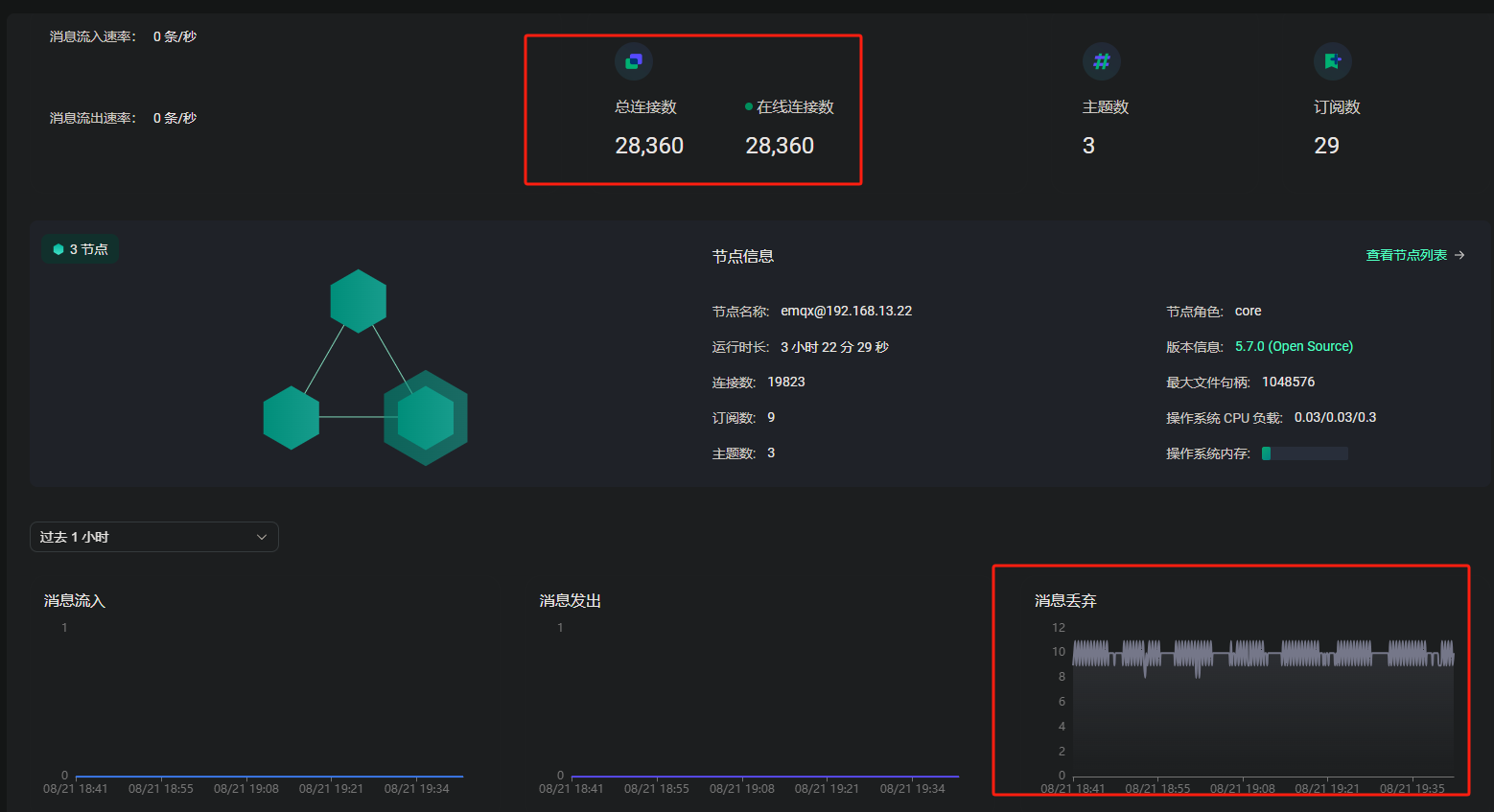
在压测情况下,保持10w连接数+10w消息吞吐量。
此时将一个core节点进行断网操作,集群会有大概几分钟的不可用时间,之后节点状态为stop。集群连接数下降、消息吞吐量下降。
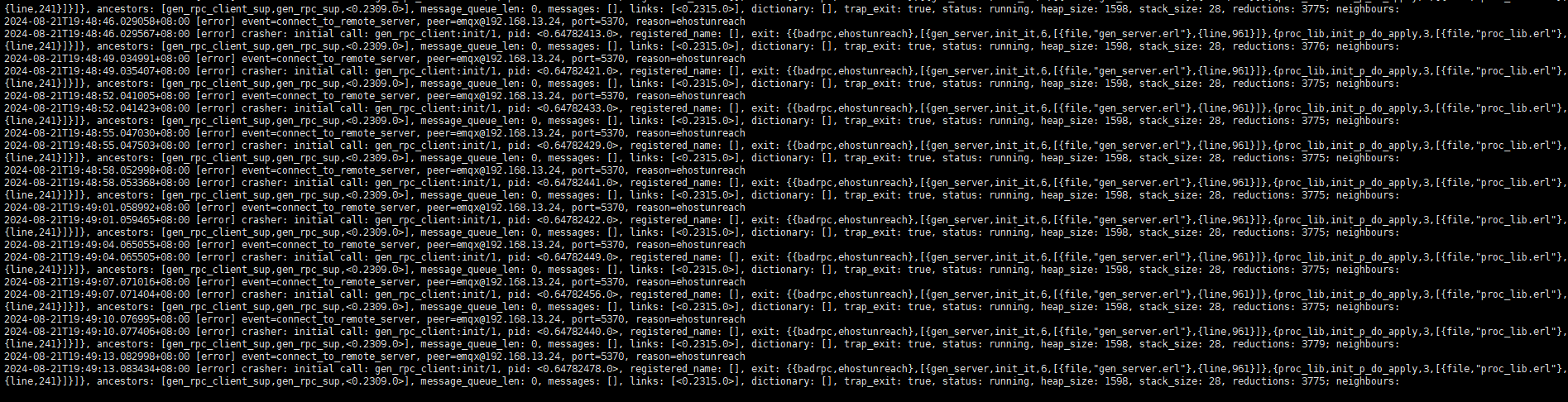
此时,假设该core节点为不可恢复节点,使用cluster leave强行剔除该节点,剔除完成后,断开所有客户端连接,查询ss -s统计相关连接已关闭,但dashboard上显示还是存在大量连接数及丢弃消息,同时查看日志,其他三个core节点也还会与该节点通信。
尝试过systemctl stop emqx,或者是restart 对集群无影响,只是在节点关机或者是网络不通情况下会产生该问题
5.问题点:
集群状态如何正确的剔除core节点,保证其他core节点的正常运行,否则core节点宕机将影响业务的正常运行,dashboard显示的连接数为什么在core节点宕机情况下不准确
感谢反馈!理论上讲,关闭其中一个节点,只应该影响该节点上的 MQTT 链接才对。其他未关闭节点不能被影响。
但断网可能情况会不太一样, EMQX 不一定即时检察到的网络断开所以肯定会打印一些错误日志的。
但,这个应该是不是期望的行为:
使用cluster leave强行剔除该节点,剔除完成后,同时查看日志,其他三个core节点也还会与该节点通信。
其次,需要补充下,这里的 断开所有客户端的链接 是怎么操作的?
用cluster leave强行剔除该节点,剔除完成后,断开所有客户端连接,查询ss -s统计相关连接已关闭,但dashboard上显示还是存在大量连接数及丢弃消息
你的问题核心应该是在 ”如何保证一个 core 节点断网后,剩余的 emqx 集群能正常的工作“
ps补充:Dashboard 这里看到的消息丢弃,只能证明存在有主题发布了,但是无客户端订阅这个主题。
只要在剩下节点的集群的 MQTT 链接和消息是正常,那这个异常测试就是通过的
补充:
目前测试过程,是使用一个共享订阅topic,例:$queue/test_topic
core1~4节点都有相应客户端订阅并发布、消费
断开所有客户端的链接 - 将所有emqtt连接kill
目前有两个异常点:
- core4断网后,剩下三个节点虽然可以工作,但是流入流出无法达到正常三节点集群的数量,下降大概30%,有产生相关脑裂告警,但是经过大概6H后,流入流出又能上涨到正常水平(正常:7.5w | 异常:5w)
2.所有连接断开,dashboard存在大量连接,此时假设core4启动(无论是否启动emqx),瞬间大量连接会清零,假设core4不启动,连接会缓慢下降
业务场景:在节点断网异常后,流入流出下降,可能会导致后续消息时延过高超时,此时对生产场景有一定影响。
感谢补充,我们本地复现试试。目前推测,问题可能在于其中一个节点断网后,EMQX其他的节点还在一直尝试和这个节点进行通信,但是可能超时了,或者底层一直在重试。从而导致了
- 共享订阅消息的投递产生超高延迟。
- 把 core4网络恢复(其他节点能探测 core4 的状态)则能立马处理一些搁置的任务
ps,好奇一个点,在执行 force leave 后,共享订阅的消息 的投递也不能能恢复过来么?
是的,force leave后也恢复不了,所以麻烦你们复现下了,暂时没想到什么处理方法。
应该是底层一直在重试,本身有设置5min不在线会剔除该节点,和leave效果是一致的,并没有办法恢复过来。
收到,我先记录到我们内部系统中。找相关的研发来跟进下
Shawn
8
如果你的断网操作是用 iptables drop 掉了报文,或者把网卡掐断、拔掉网线这种的情况,那么底层 TCP 报文是在做重传的,会导致发送消息的应用都在等待 TCP ACK。这种情况你可以把 TCP 重传次数设置少一些,默认可能是 15:
sysctl -w net.ipv4.tcp_retries2=5
当然你的断网如果不是这么操作的,就不是这种问题。
断网操作就是以上所说的,拔掉网线或者在系统停止网卡;
tcp重传可以理解,只是还是与上面所说的一致,core4被集群剔除后,core4的所有相关信息应当被集群清理吧,这样不会影响到其他三节点的流入流出速率。但是目前的测试现象是影响的,且恢复时间过长(6H)
Shawn
10
Linux TCP 重传次数默认应该是 15 次,整个重传完成至少花费十几分钟,然后应用层才能感知到对面网路出了问题。这期间 EMQX 的发送端口被阻塞了,导致发送进程没办法响应任何请求。
十几分钟后 TCP 失败发送进程才会断开 TCP 连接,但已经太晚了,系统可能已经堆积了太多的请求后面很难再恢复回来。
这是一个常见的问题,tcp_retries2 应该设置短一些。
那我们先通过这种方式再测试一轮,看看现象是否会改善