[warning] msg: busy_dist_port, portinfo: [{port,#Port<0.8>},{name,“tcp_inet”},{links,[<0.2712.0>,<0.2179.0>]},{id,64},{connected,<0.2712.0>},{input,1159826443},{output,174},{os_pid,undefined}], procinfo: [{pid,<0.4284.0>},{memory,29768},{total_heap_size,3358},{heap_size,2586},{stack_size,26},{min_heap_size,233},{proc_lib_initial_call,{emqx_broker,init,[‘Argument__1’]}},{initial_call,{proc_lib,init_p,5}},{current_stacktrace,[{mnesia_tm,async_send_dirty,6,[{file,“mnesia_tm.erl”},{line,2076}]},{mnesia_tm,dirty,2,[{file,“mnesia_tm.erl”},{line,1140}]},{emqx_broker,handle_cast,2,[{file,“emqx_broker.erl”},{line,553}]},{gen_server,try_handle_cast,3,[{file,“gen_server.erl”},{line,1121}]},{gen_server,handle_msg,6,[{file,“gen_server.erl”},{line,1183}]},{proc_lib,init_p_do_apply,3,[{file,“proc_lib.erl”},{line,241}]}]},{registered_name,emqx_broker_32},{status,suspended},{message_queue_len,22},{group_leader,<0.4032.0>},{priority,normal},{trap_exit,false},{reductions,2864959},{last_calls,false},{catchlevel,2},{trace,0},{suspending,},{sequential_trace_token,},{error_handler,error_handler}]
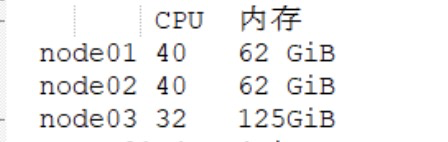
压测发布50w消息的时候,emqx出现这样的告警,是需要优化什么吗?需要怎么进一步处理呢?