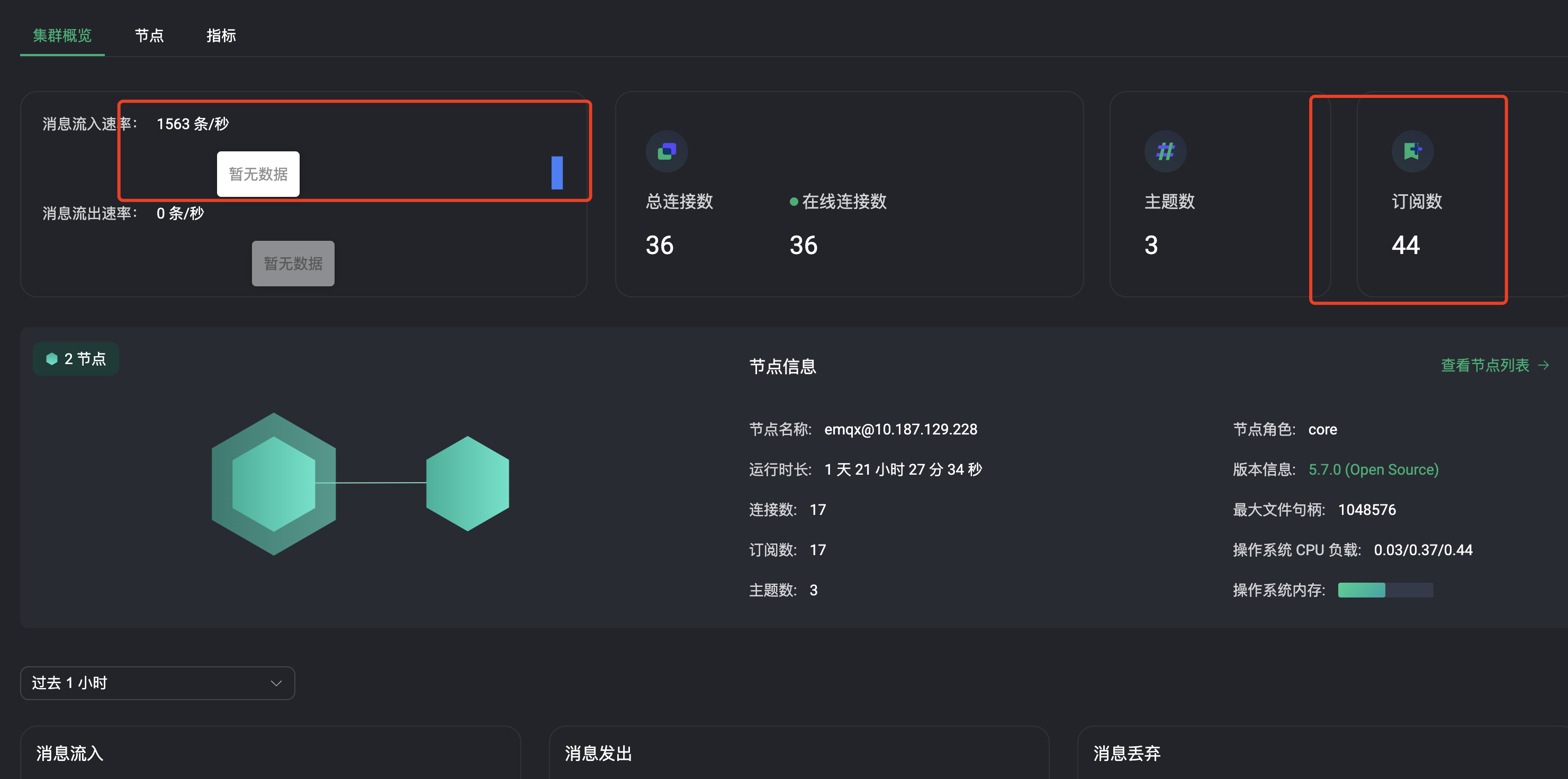
版本:5.7.0 两个节点组成的集群
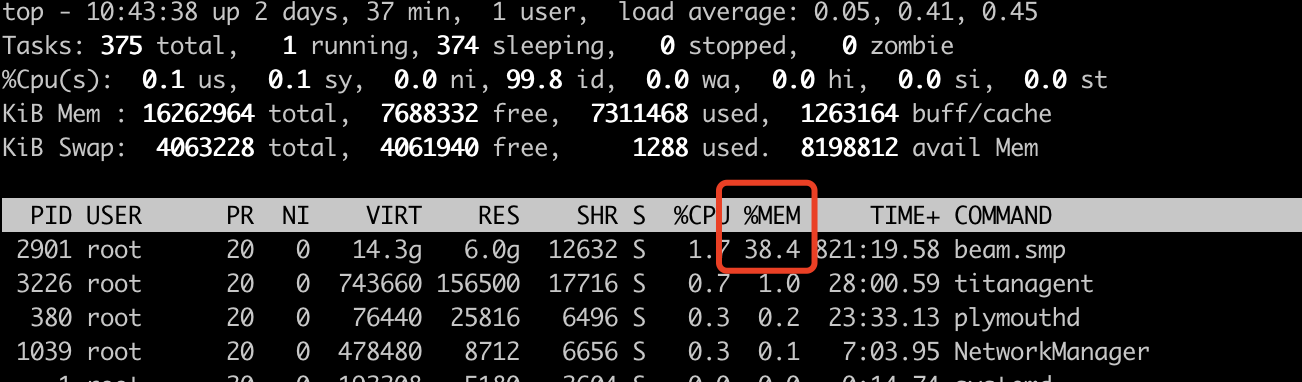
dashboard有内存告警
订阅数很少,每秒会有一个1500笔消息推送,无订阅端,消息推送到即丢弃
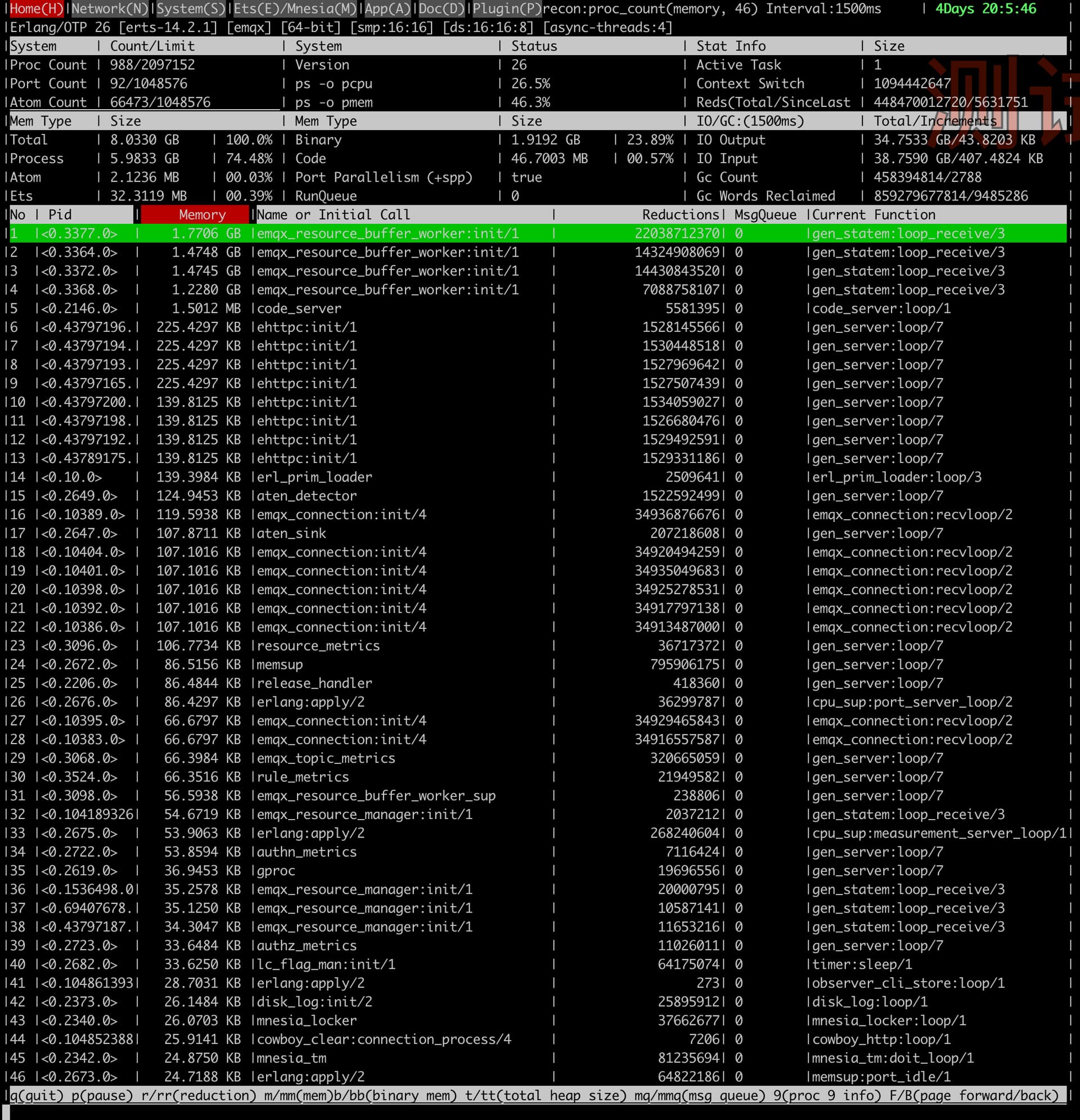
试试这个看看,那些内部的进程占用内存比较大呢
./bin/emqx eval 'observer_cli:start()'
重新连接了连接器之后就掉下去了,我把日志上传一下
emqx.log.1.zip (150.6 KB)
起因是规则引擎连接的那台机器挂掉了,机器重启后重连了,但显示集群两个节点不同步,我手动点了下更新,显示成功了,然后后面就有内存告警了;接下来就慢慢的在排查了,关闭规则、关闭连接器,后面就发现内存掉下来了;然后再重启规则、连接器内存也没有上升;后面看日志发现有持续的报错
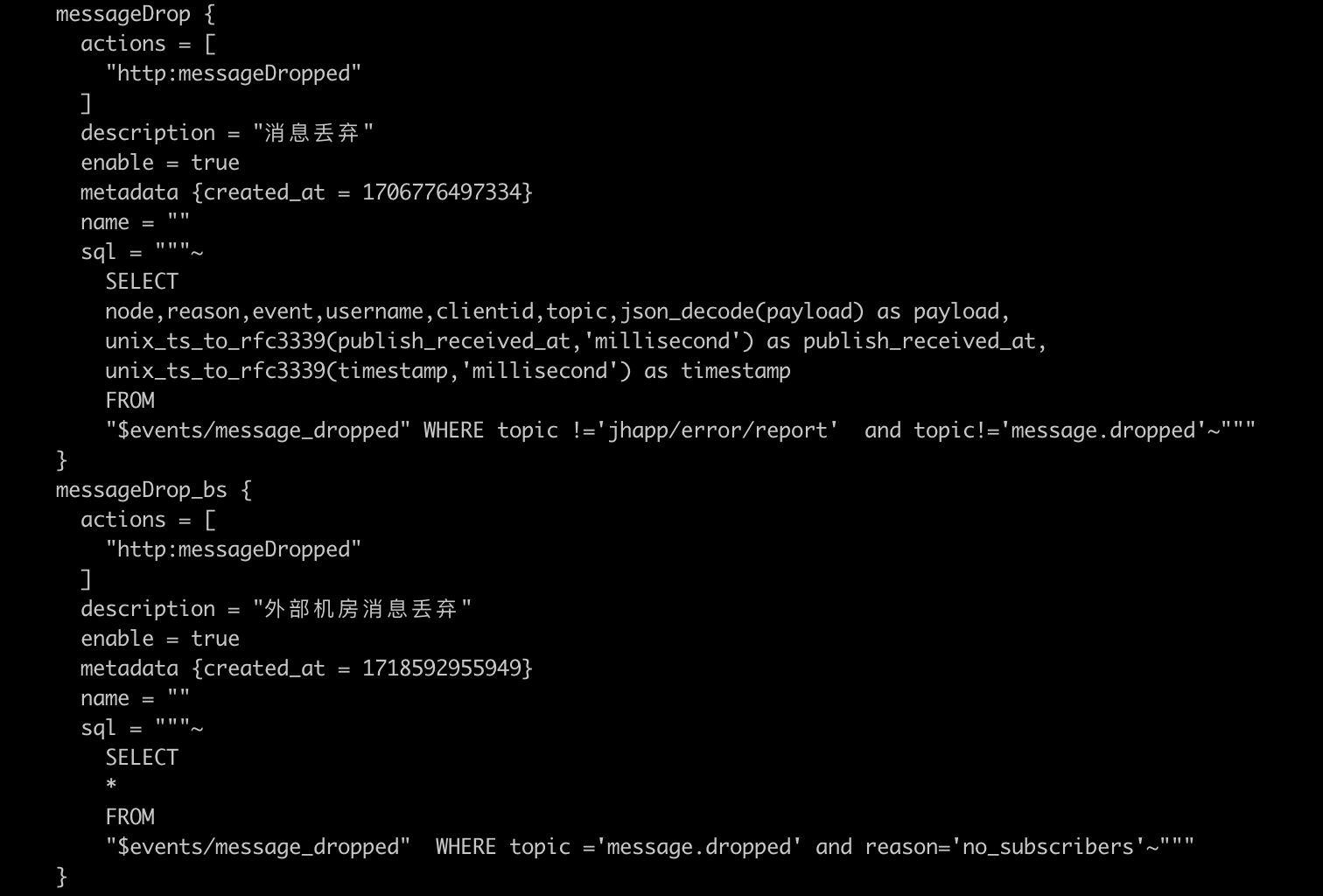
看起来有点奇怪。你是说你的大部分消息都是发到http:messageDropped 里面的么。
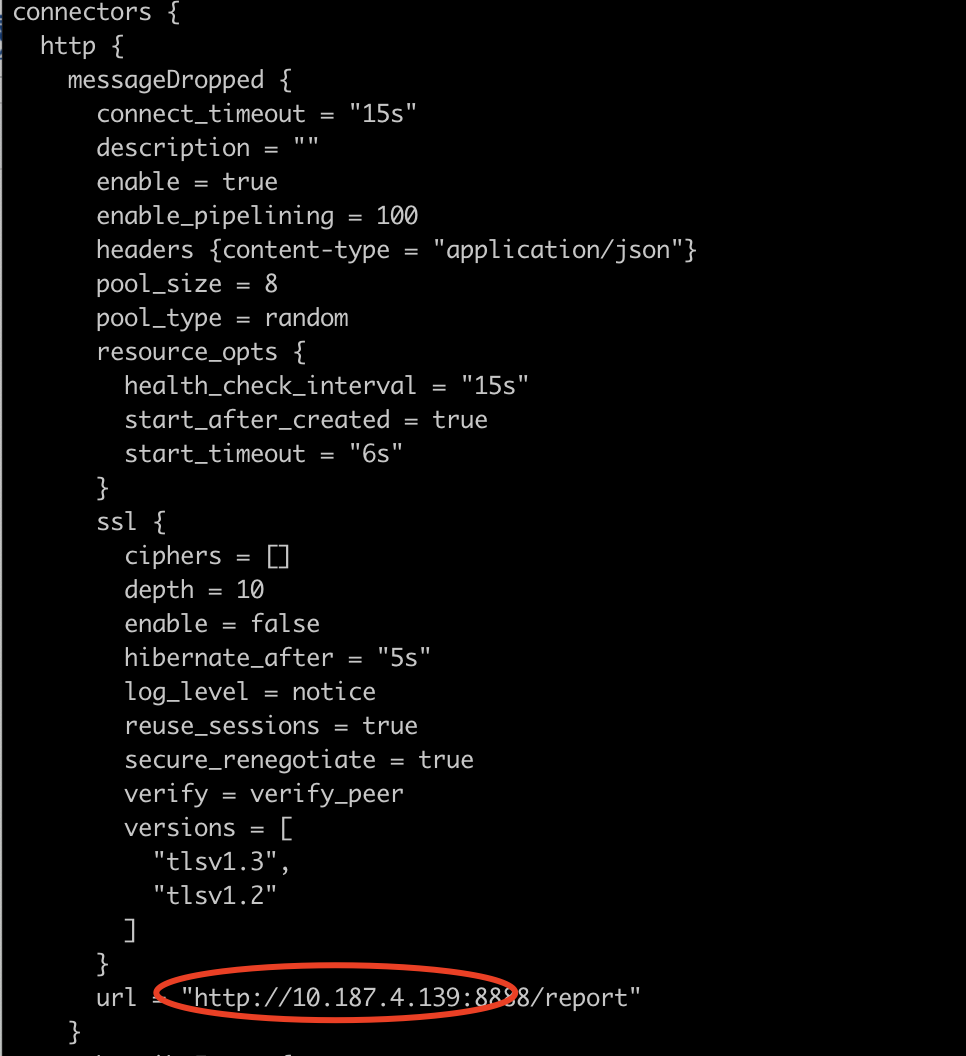
可以看看你的 connectors rule_engine 配置么
./bin/emqx ctl conf show connectors
./bin/emqx ctl conf show rule_engine
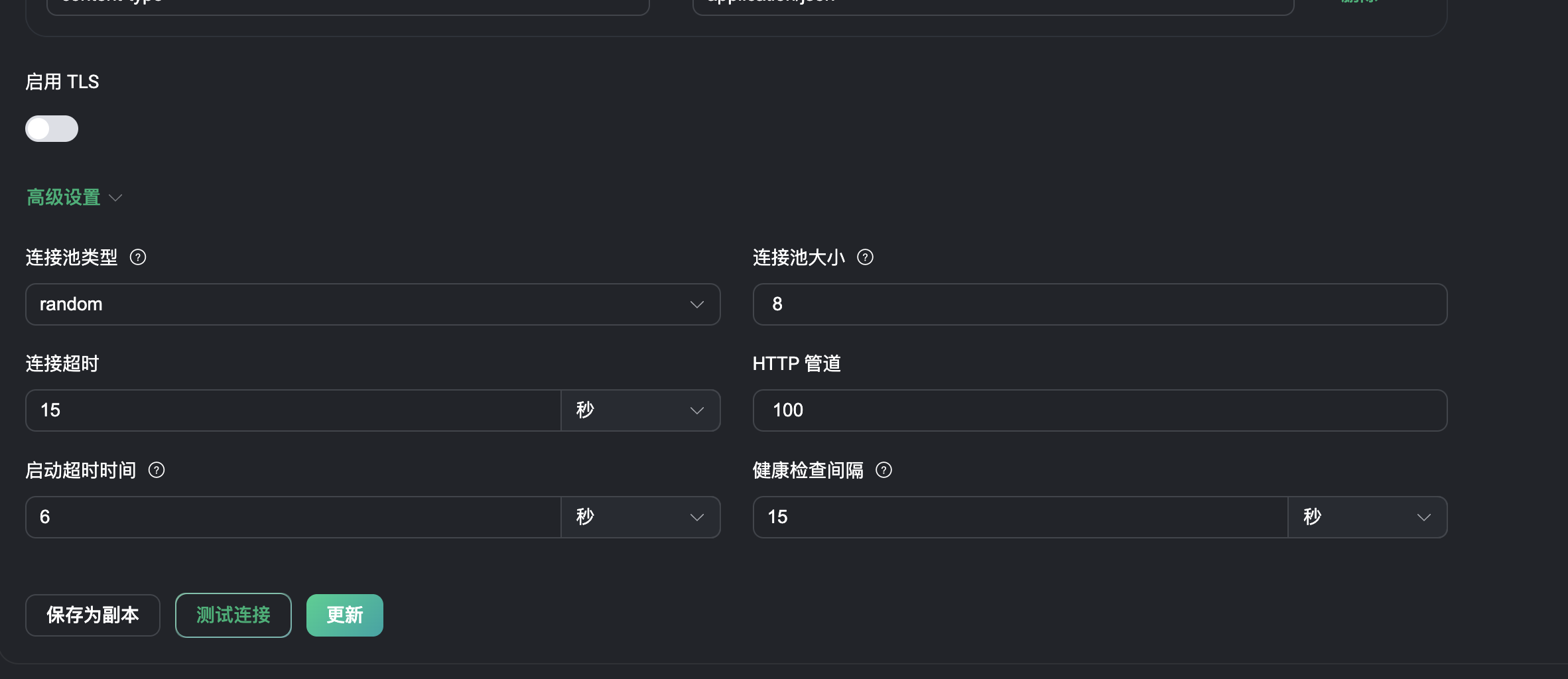
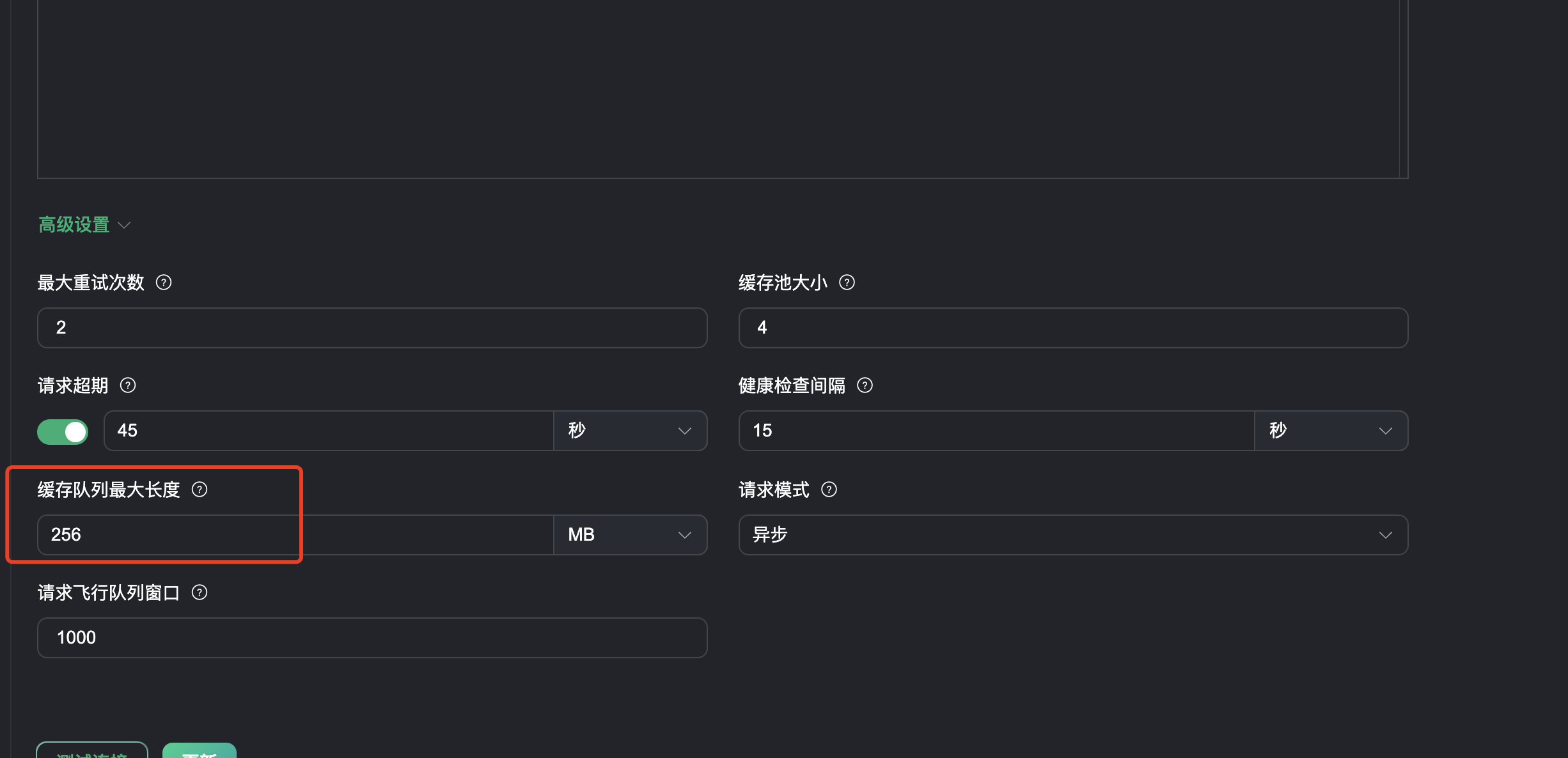
连往 4.139有一个连接池( pool_size=8条连接),他对应的 actions 有一组 buffer ,默认是会缓存max_buffer_bytes 大小的。你可以用
./bin/emqx ctl conf show actions
看看。
可以在 actions 的界面的高级选项里面把他调小一点。
我还有个问题,这个缓存在重新连接后不会清掉吗?或者什么时候会出发清缓存的条件
看了上面你给伯日志。没看明白为什么会内存这么高。
能同志传一下最新的内存高时的那一台 emqx 的日志。并再传一下 observer_cli的那个图么
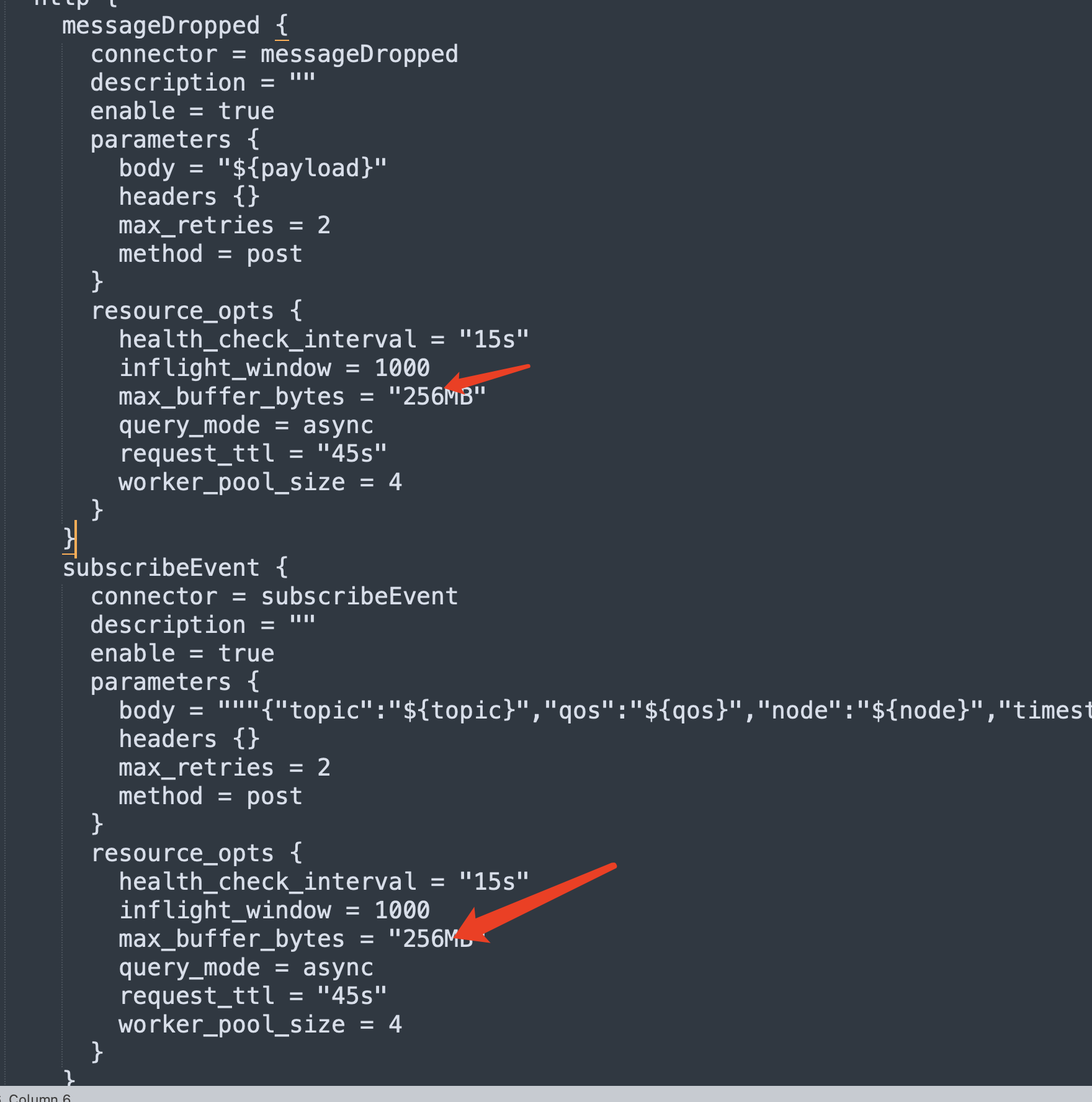
./bin/emqx ctl conf show actions 看看有什么 actions,需要看到完全的所有 actions。
actions {
http {
messageDropped {
connector = messageDropped
description = “”
enable = true
parameters {
body = “${payload}”
headers {}
max_retries = 2
method = post
}
resource_opts {
health_check_interval = “15s”
inflight_window = 1000
max_buffer_bytes = “256MB”
query_mode = async
request_ttl = “45s”
worker_pool_size = 4
}
}
subscribeEvent {
connector = subscribeEvent
description = “”
enable = true
parameters {
body = “”“{“topic”:”${topic}“,“qos”:”${qos}“,“node”:”${node}“,“timestamp”:${timestamp},“payload”:”${payload}“}”“”
headers {}
max_retries = 2
method = post
}
resource_opts {
health_check_interval = “15s”
inflight_window = 1000
max_buffer_bytes = “256MB”
query_mode = async
request_ttl = “45s”
worker_pool_size = 4
}
}
}
mqtt {
bridge {
connector = bridge
description = “”
enable = true
parameters {
qos = “${qos}”
retain = “${flags.retain}”
topic = “${events}”
}
resource_opts {
health_check_interval = “15s”
inflight_window = 100
max_buffer_bytes = “256MB”
query_mode = async
request_ttl = “45s”
worker_pool_size = 16
}
}
lalDcTobaoshanDc {
connector = bsBridge
description = “”
enable = true
parameters {
payload = “${payload}”
qos = “${qos}”
retain = “${flags.retain}”
topic = “${topic}”
}
resource_opts {
health_check_interval = “15s”
inflight_window = 100
max_buffer_bytes = “256MB”
query_mode = async
request_ttl = “45s”
worker_pool_size = 16
}
}
}
}
这是进程池中每个进程的最大 buffer_bytes:
比如你现在的 worker_pool_size 是 4,那缓存的数据可以达到 4*256M=1G。并且还会超出一点。
在没找到问题之前(我明天再研究一下),你可以再设置小一点。
并且 出现问题后,关停一下 action 就好了。
好的,现在没有这个问题,只有当机器挂了的时候才会出现,其他时间都是正常的,之前应该也出现过机器挂的情况,只不过当时没有数据推送;这个缓存连上之后就一直不会消失吗?应该会有个过期时间,或者重连之后缓存的数据应该也能继续发送