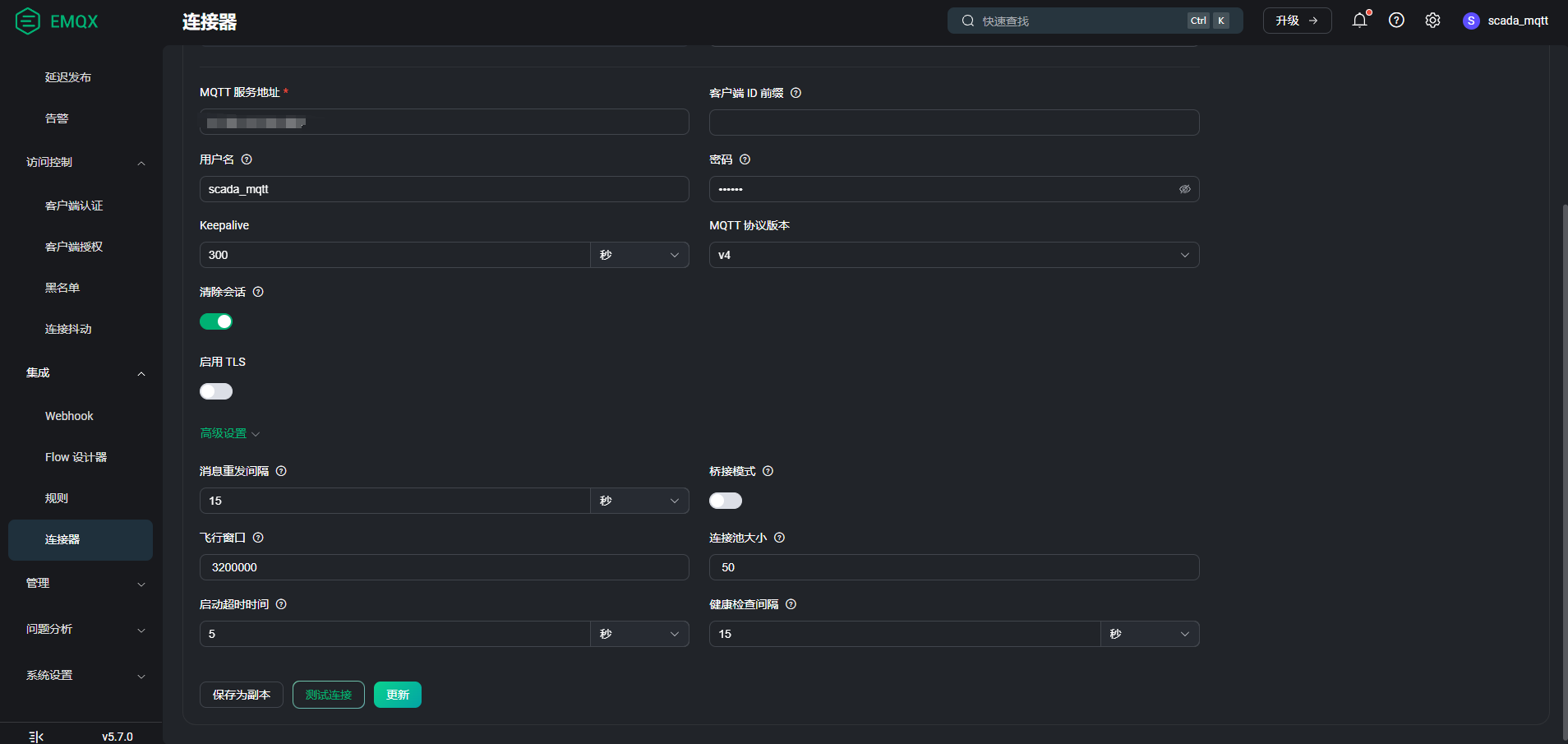
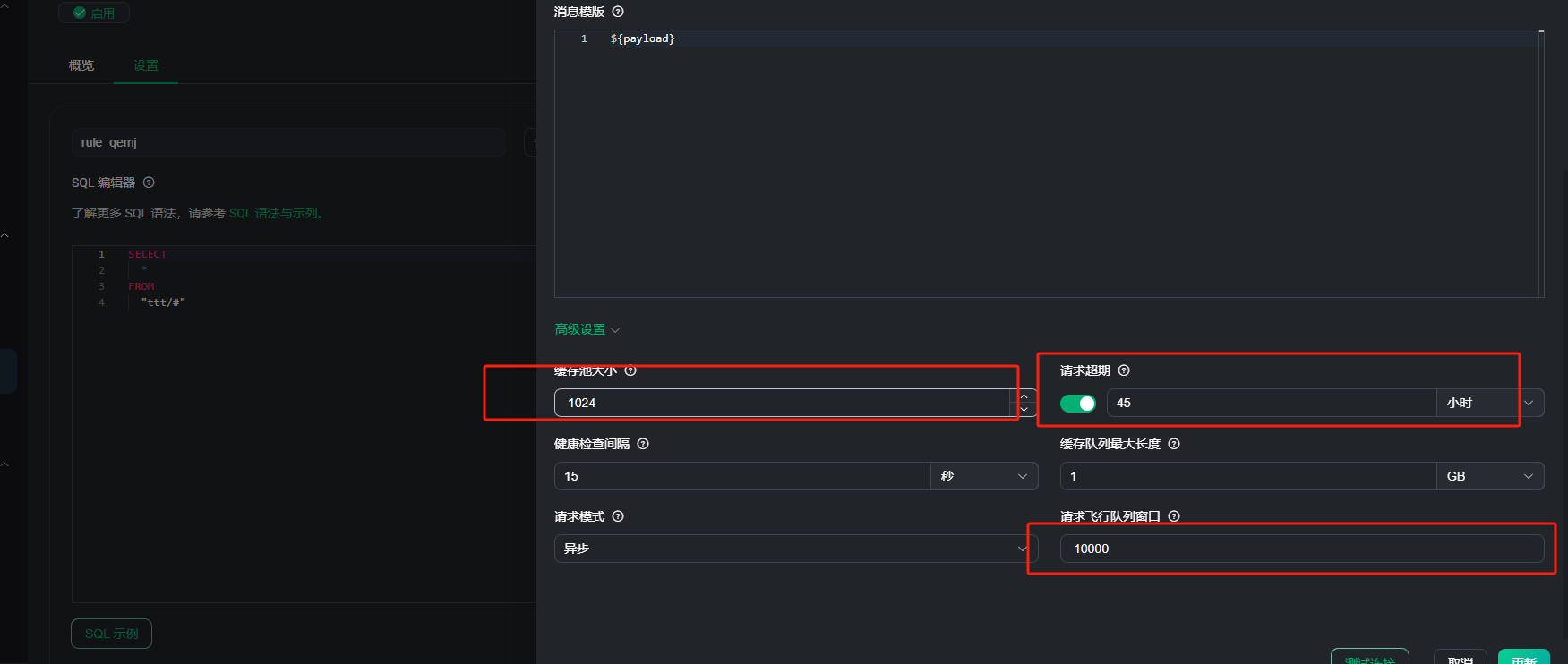
emqx 5.2.0 使用规则引擎把数据推送到另一个EMQ,会发生很多数据丢失败问题,请问原因是什么呢?
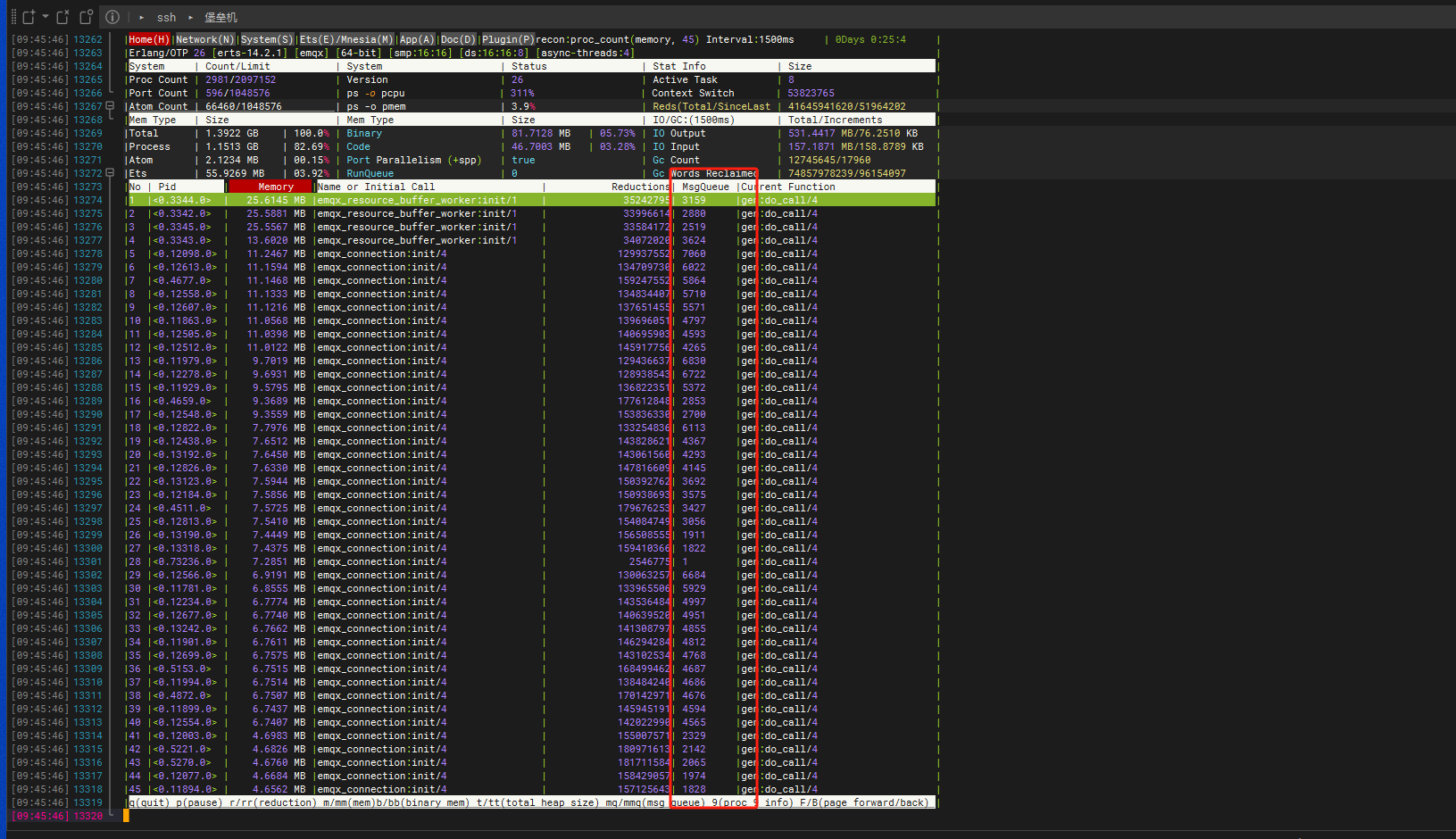
使用./emqx eval ‘observer_cli:start()’ 查到
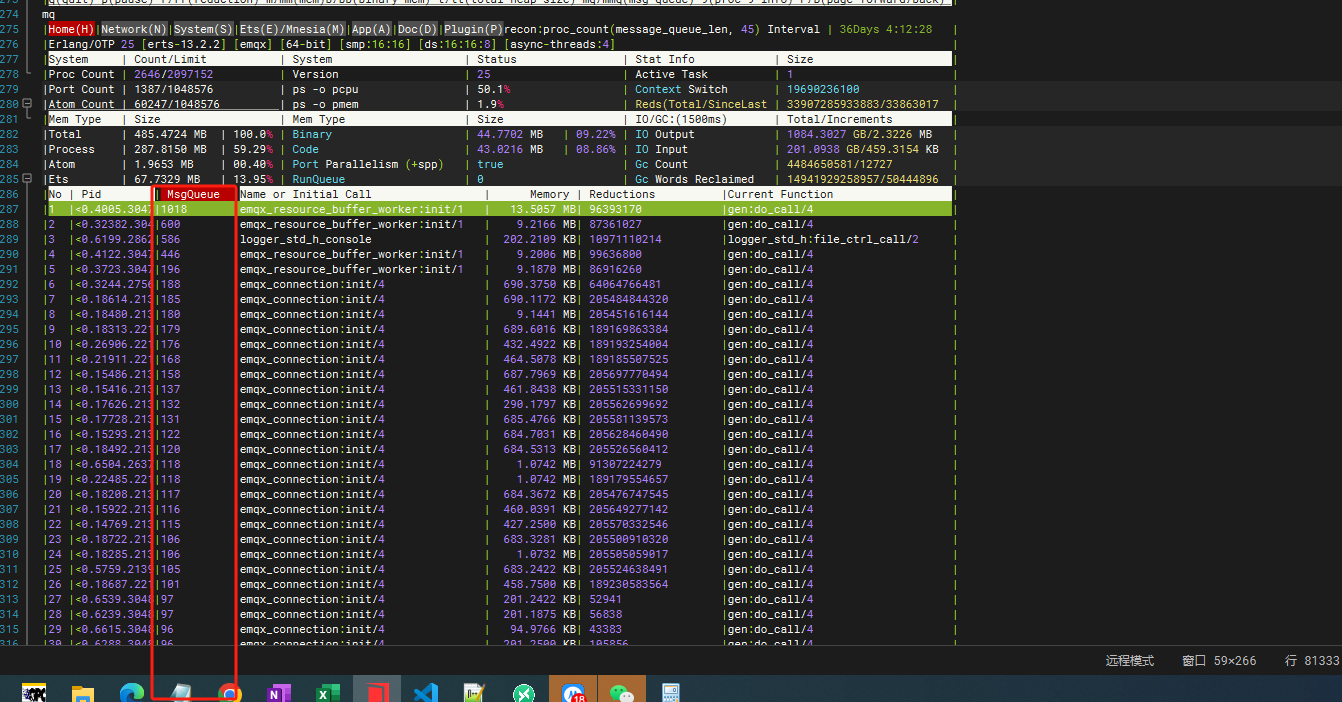
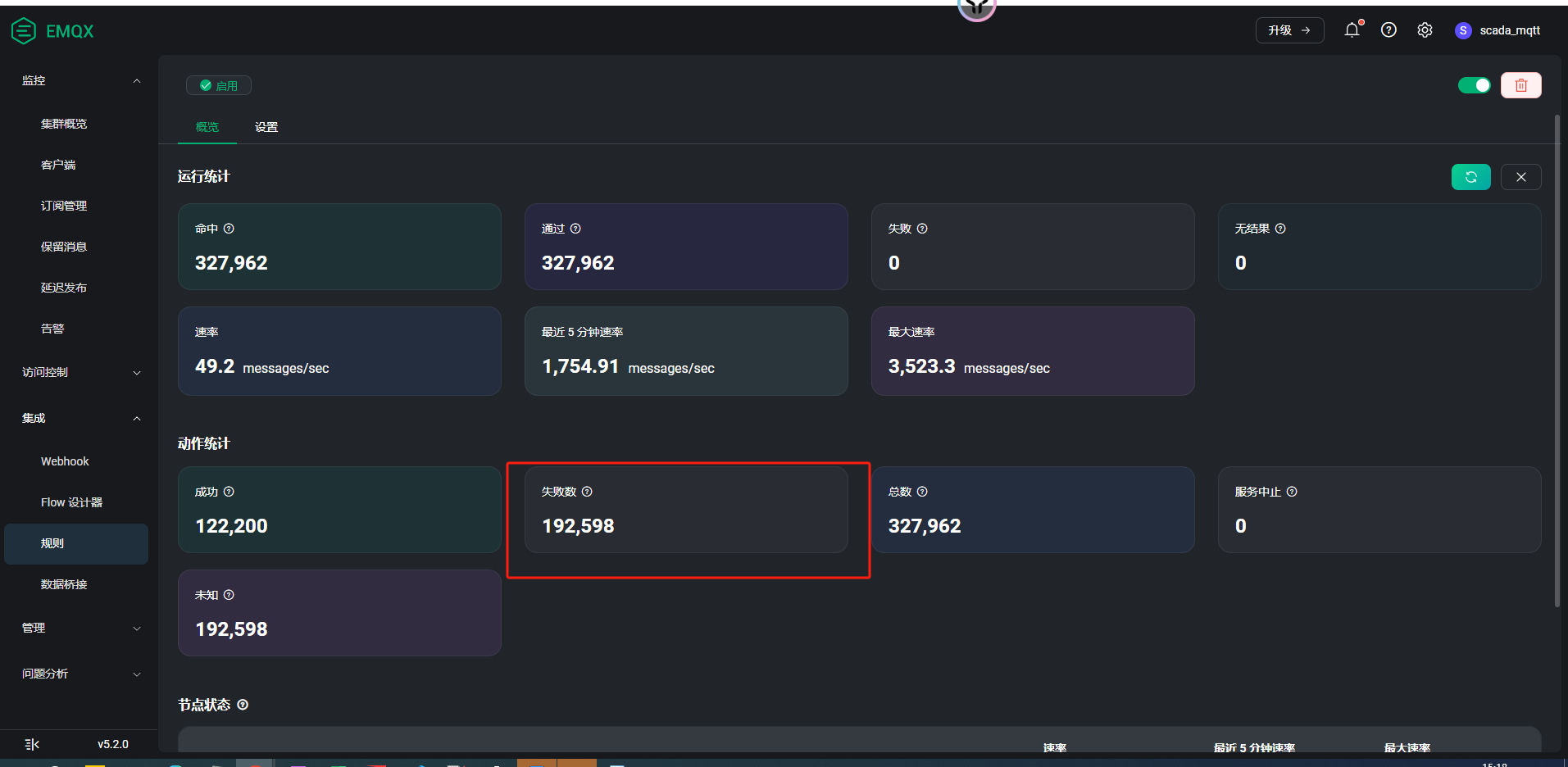
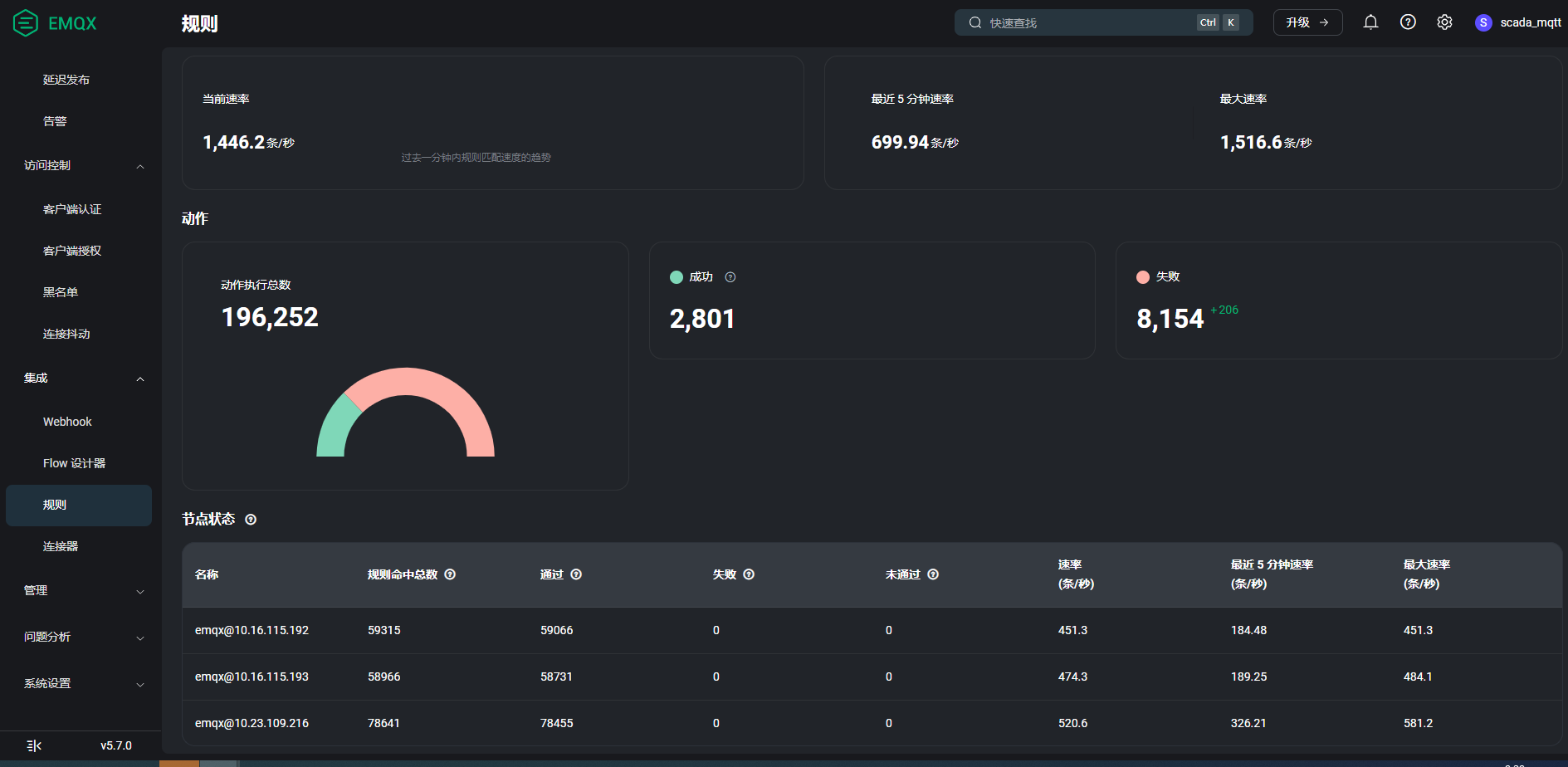
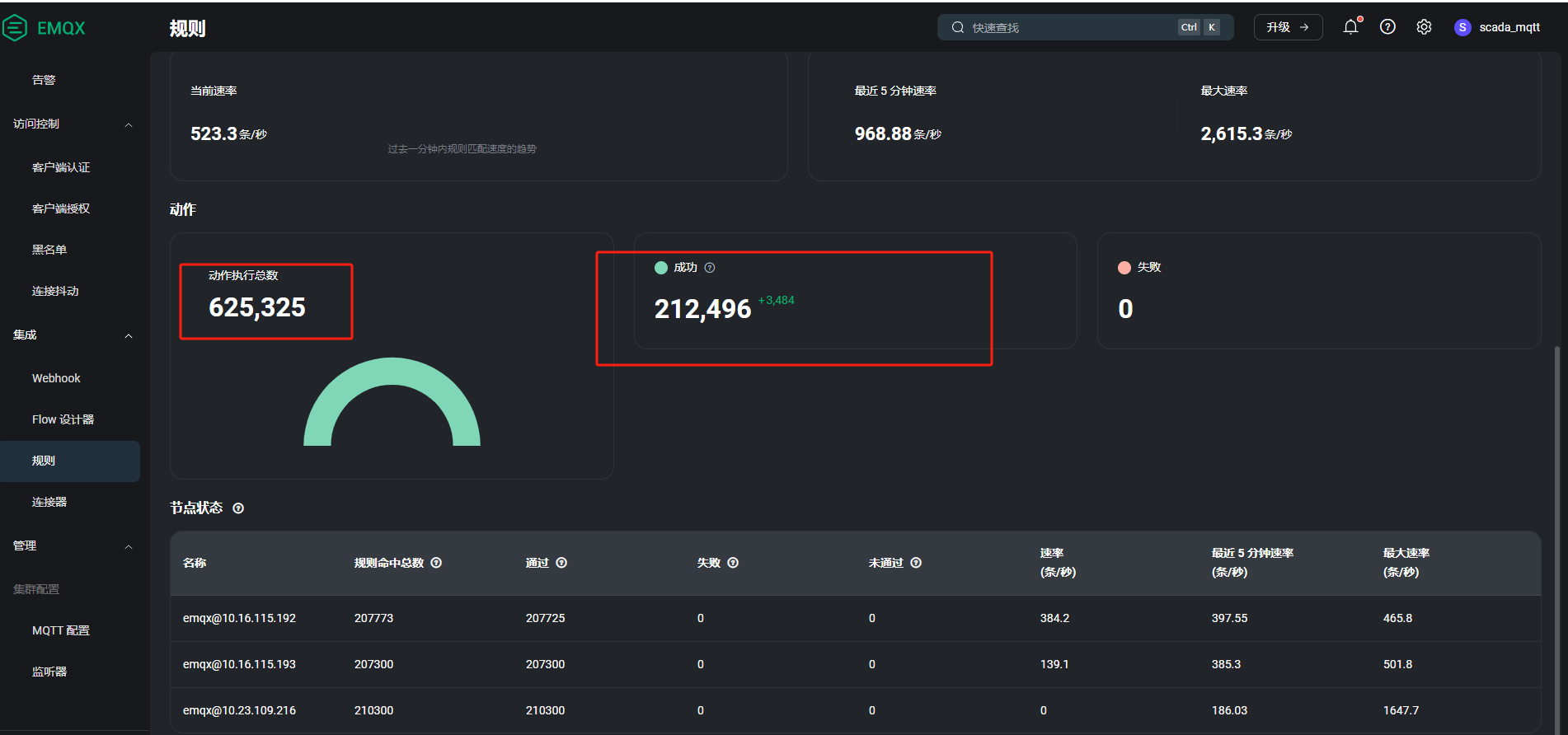
怎么查看队列数是否已满呢?下图的失败数产生的原因跟队列数有关吗?
emqx 5.2.0 使用规则引擎把数据推送到另一个EMQ,会发生很多数据丢失败问题,请问原因是什么呢?
使用./emqx eval ‘observer_cli:start()’ 查到
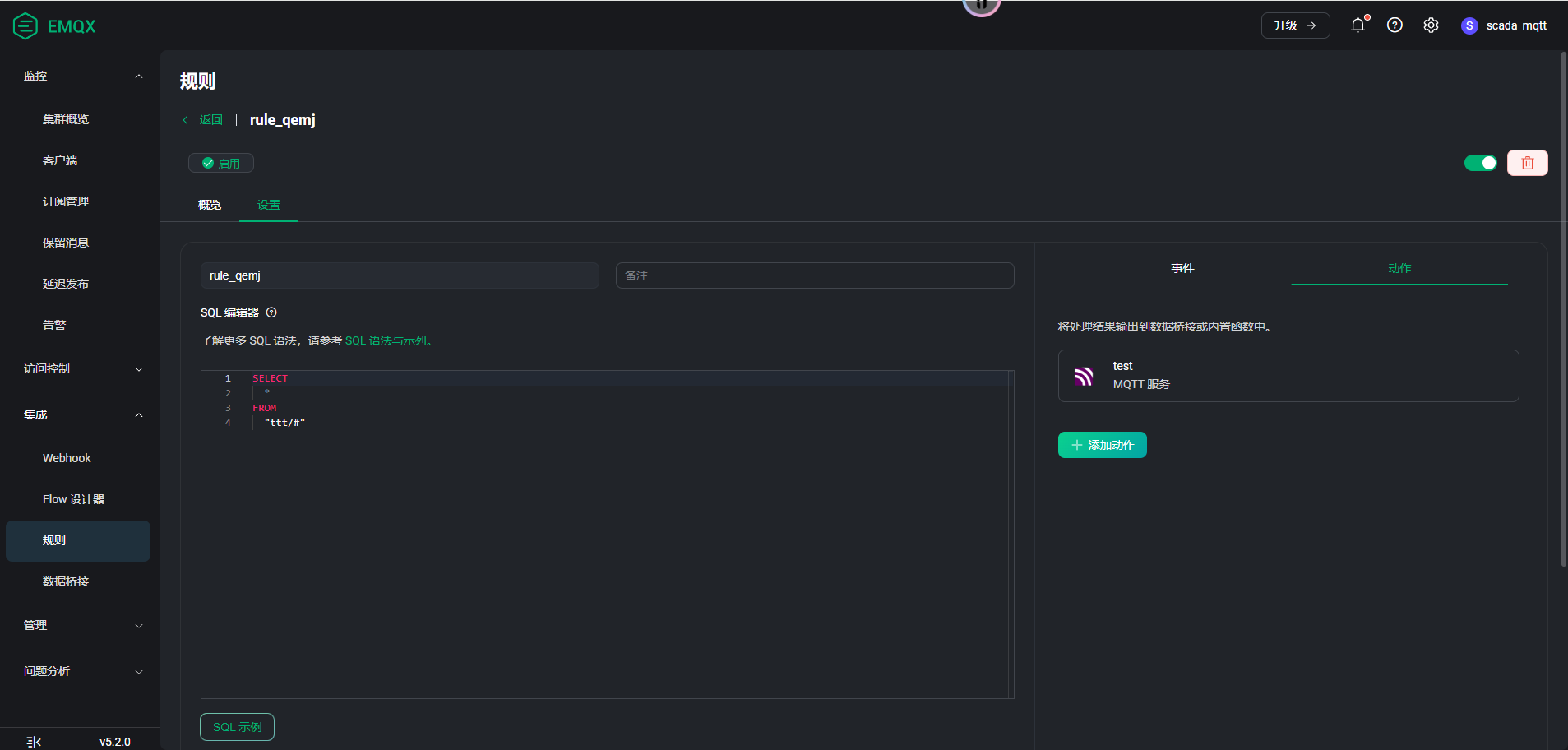
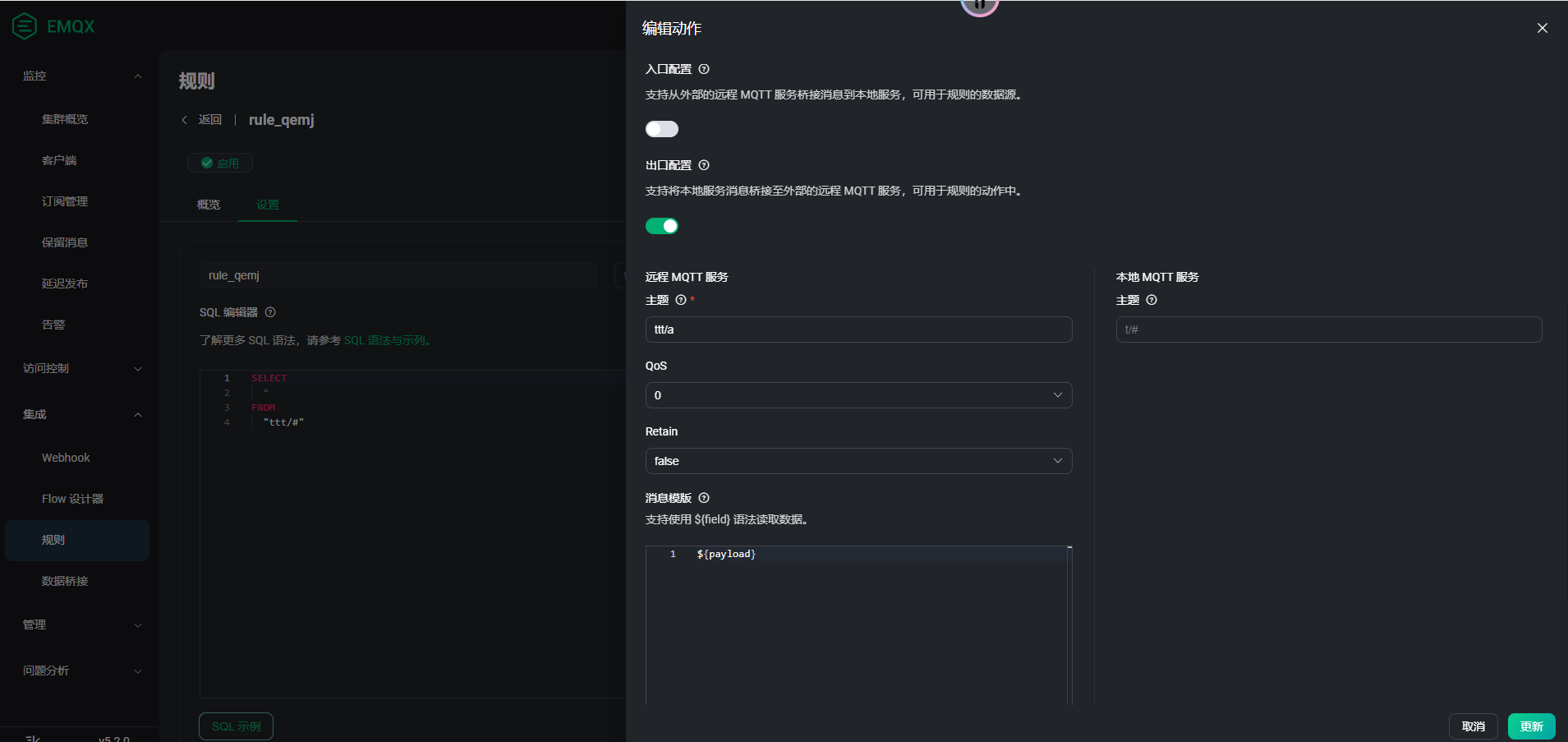
请问具体是什么场景需要这样设计,还有规则的配制和日志文件最好都提供下
建议使用最新的版本试试,5.x 早期版本里 MQTT 桥接实现上有些性能问题。
好的,我先升级最新版本5.7试一下
麻烦把 MQTT 桥接的配制和 log 文件发下
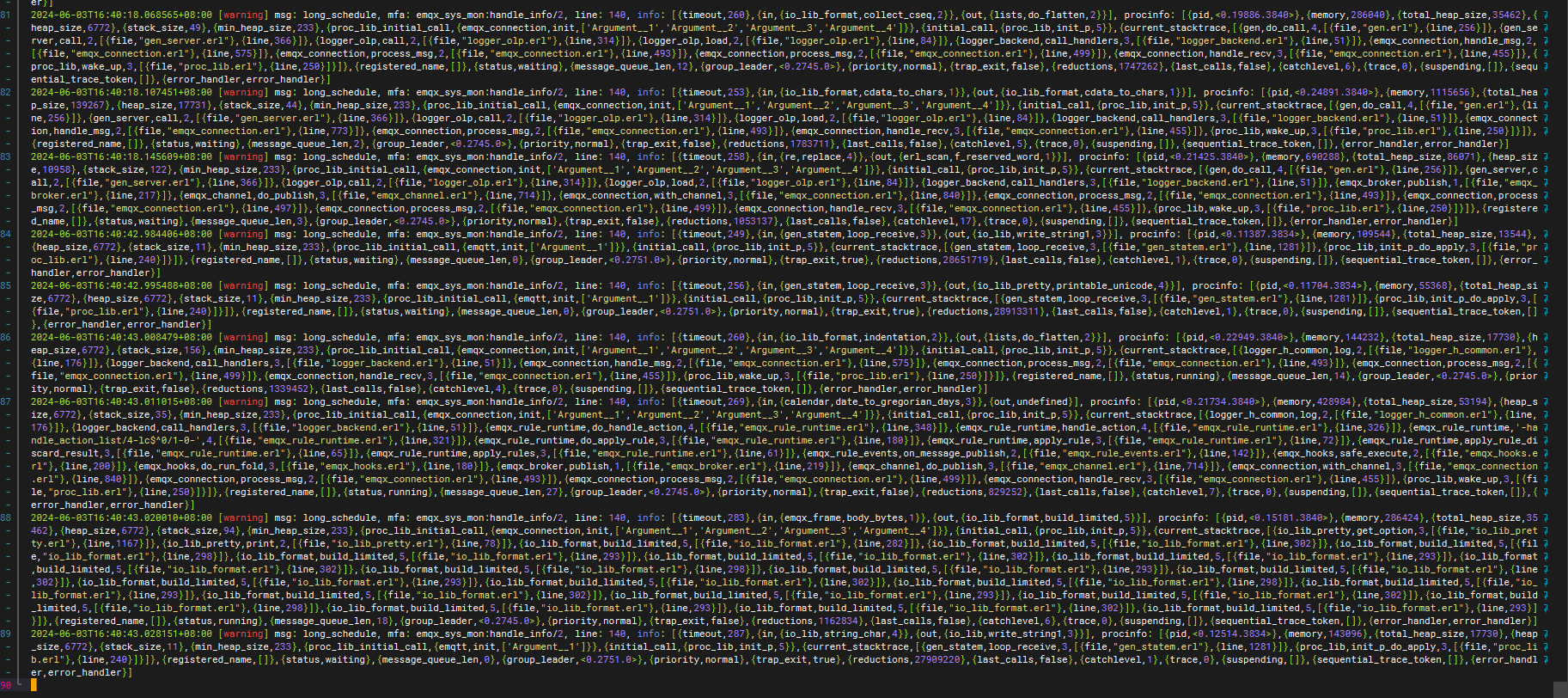
我看了你的 log 文件,里面基本没有和规则相关的内容,麻烦将 log 等级设置为 debug, 然后重新生成一份日志。
从目前的信息来看,问题出在远端的 broker 上,看起来是远端处理能力不够
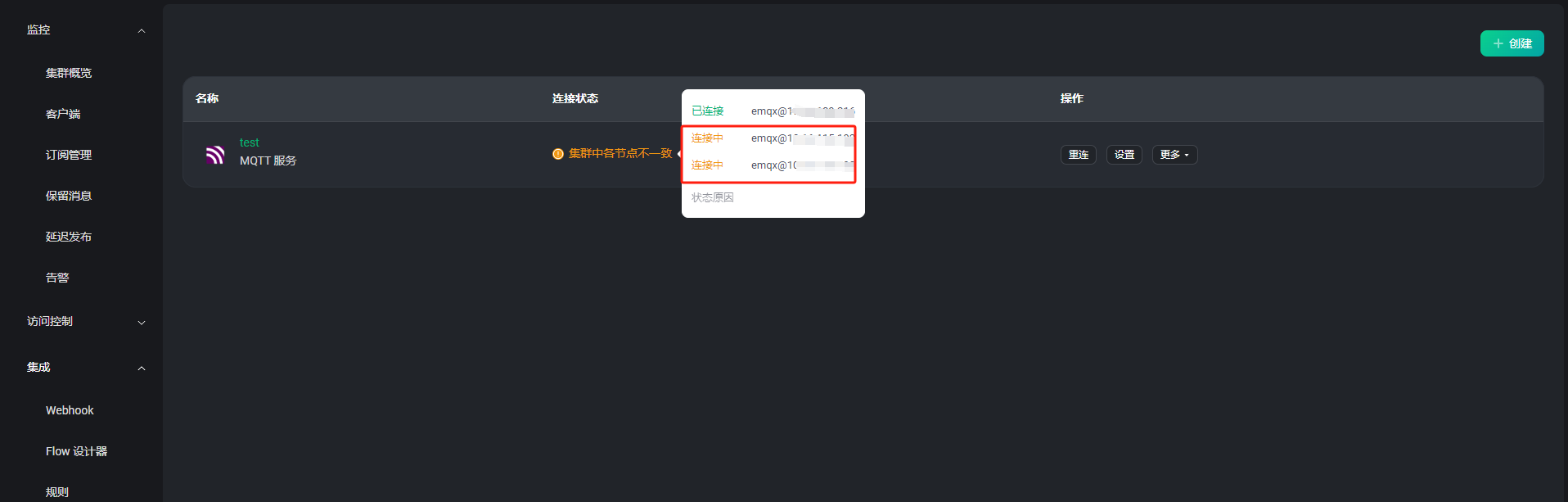
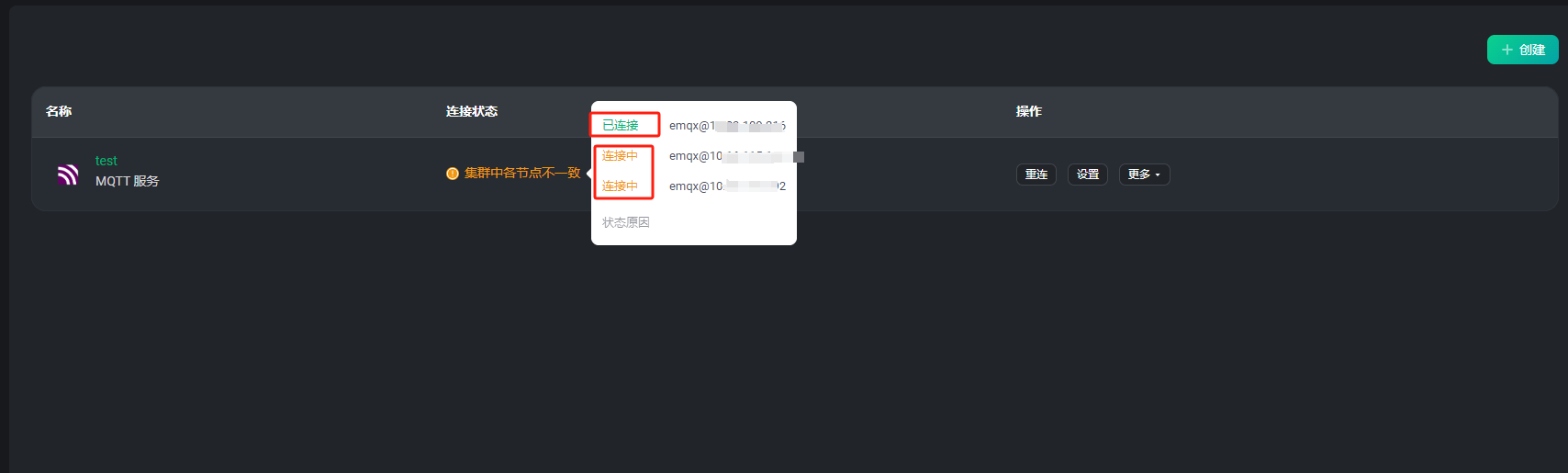
建议先排查和解决资源不一致的问题,再重新验证下。
你现在提供的日志里没有有效的和资源相关的内容,不太好分析具体原因
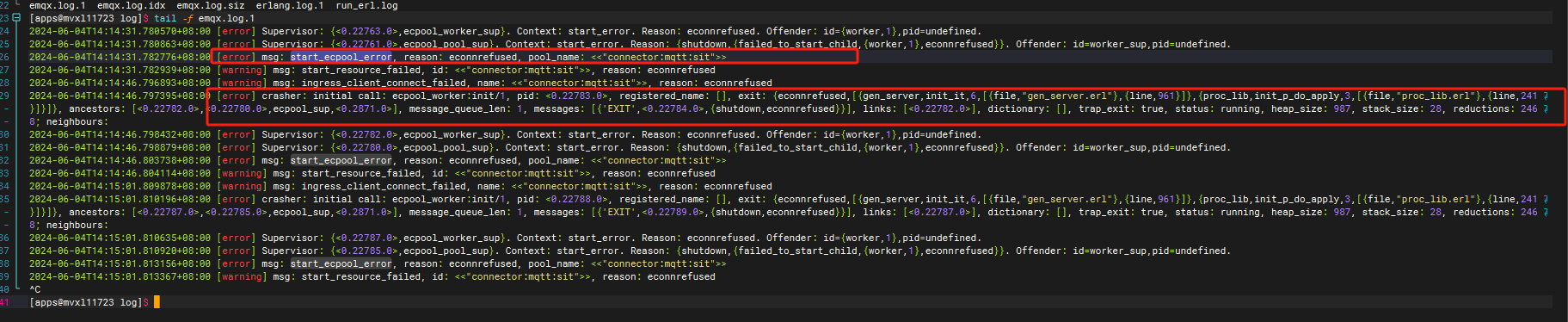
econnrefused 是连接被拒绝了,这个不是资源断开,是根本就没有成功连上
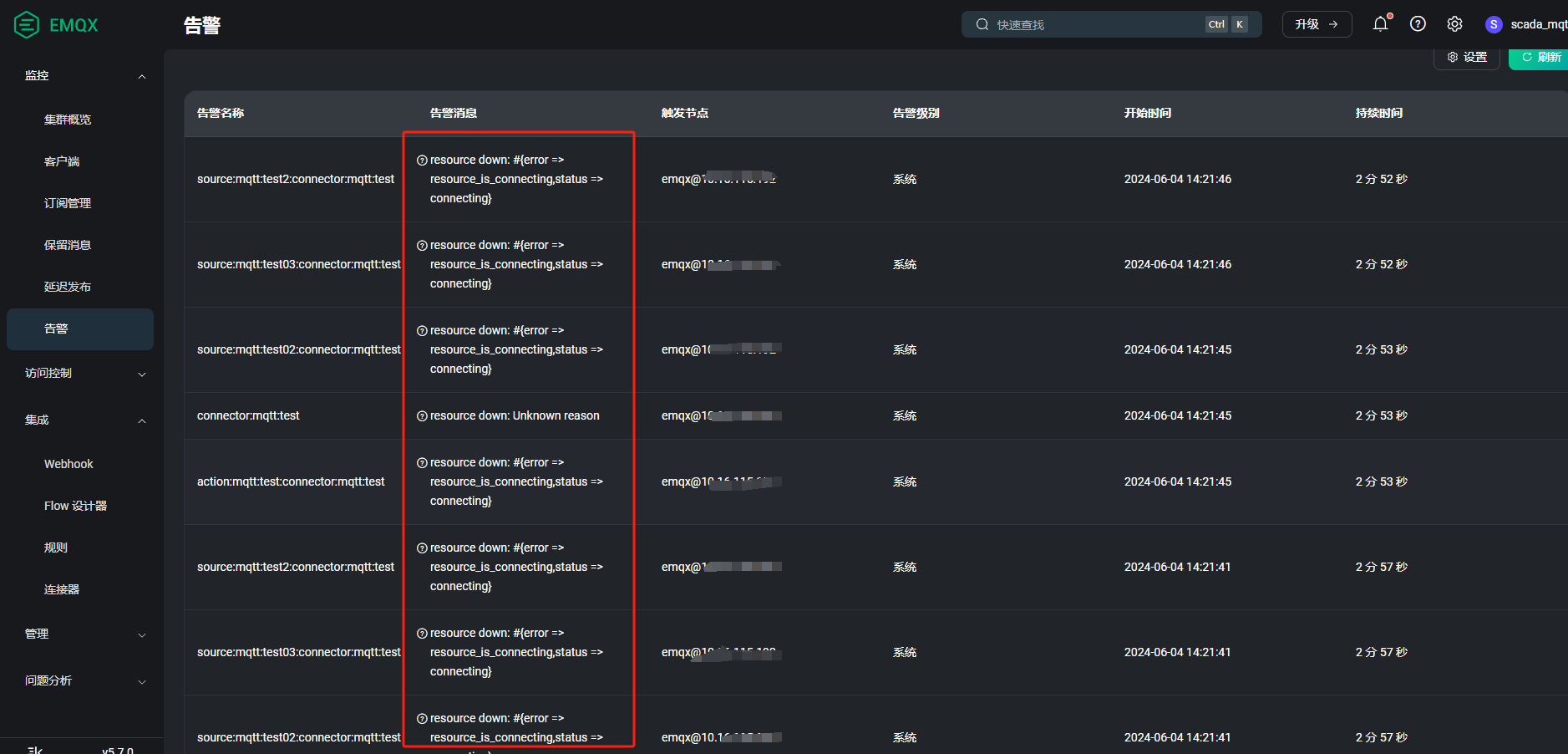
这个告警显示资源连接没有成功,然后在不断的重连。
我在这个日志里面看到 2024-06-04T14:47:01.734510+08:00 [debug] msg: ingress_publish_local,这个是远端的节点的日志么?这个日志看没有问题,收到消息,然后 republish,也没有异常等。
这是本地的日志,我因为换了另一个方式,是通过订阅远端的数据重发布到本地,目前没找到节点不一致的问题,但这个现象的产生都是出现在我们压测时大并发订阅远端数据导致的
结合你之前的截图来看,上行会话里都存在大量的积压消息,所以能看出上行的数据量很大,然后又会全部推到远端,这种情况下,需要注意: