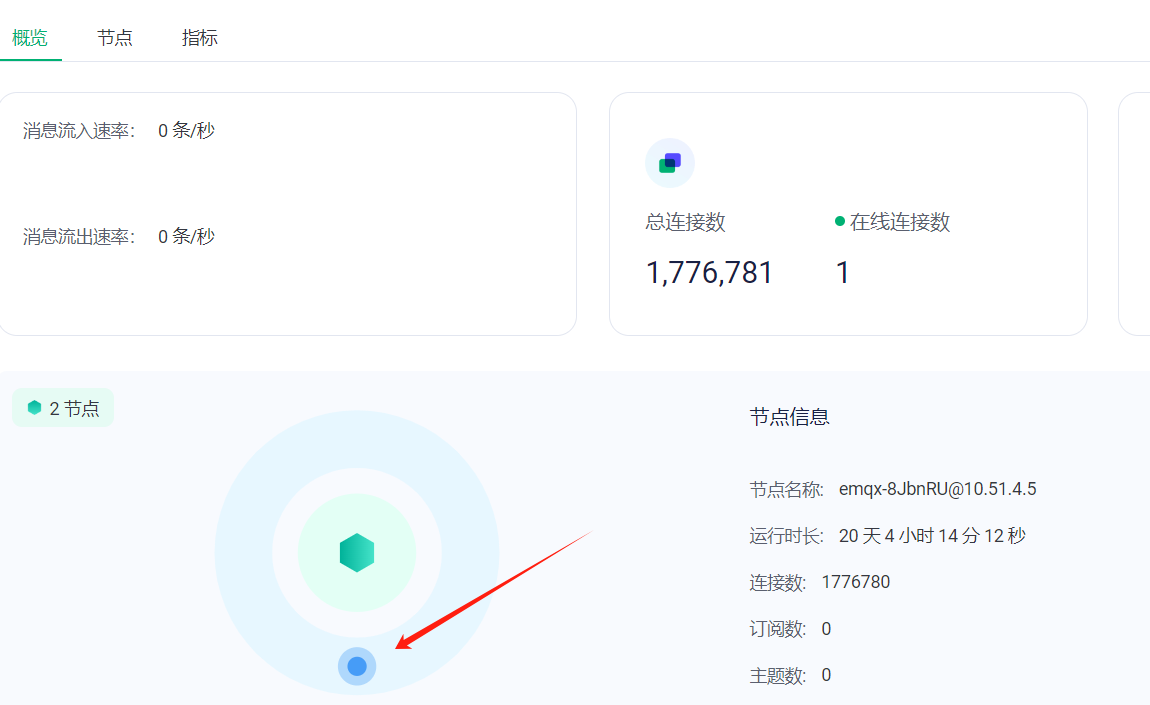
问题: 总连接数是20001, 在线连接数是0,但是在客户端界面。都显示为已连接, 且无法踢掉
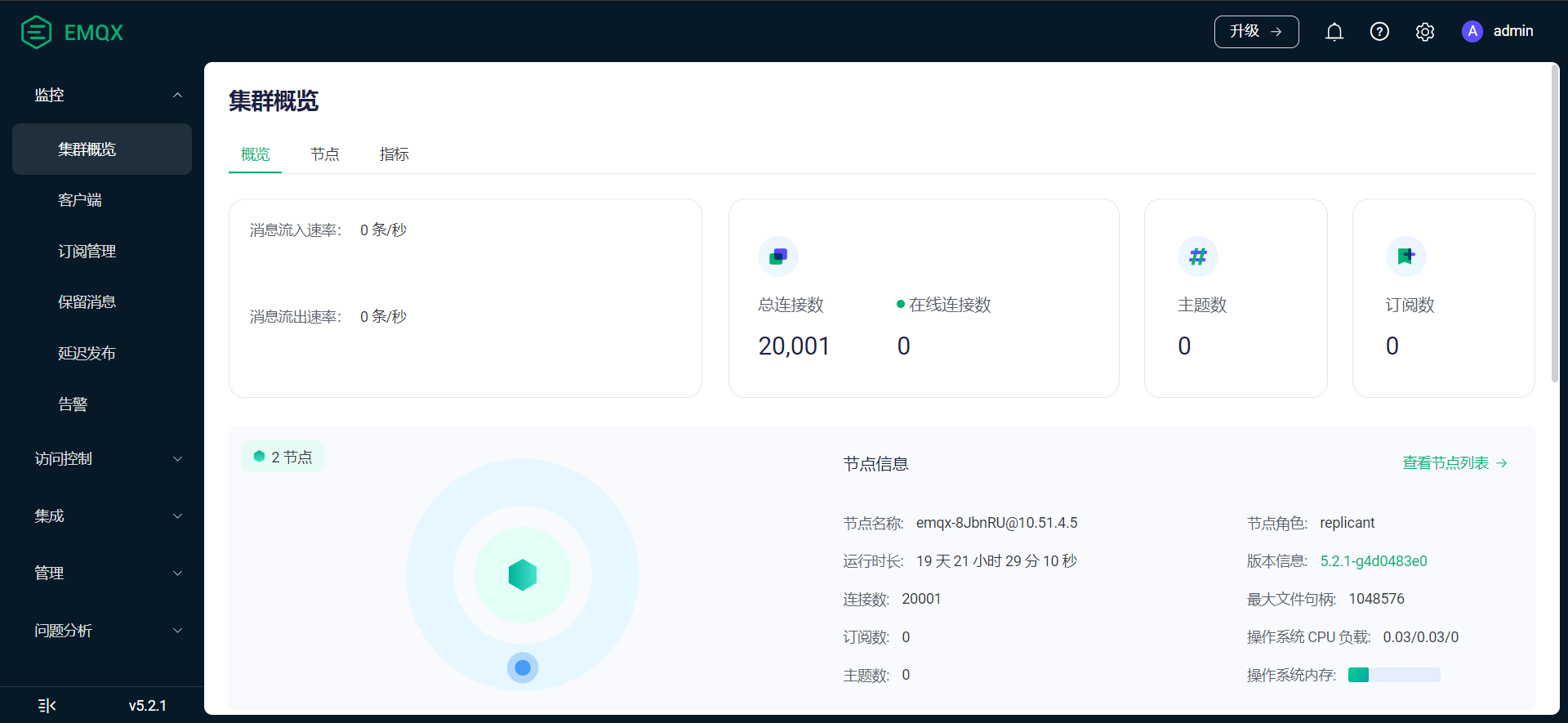
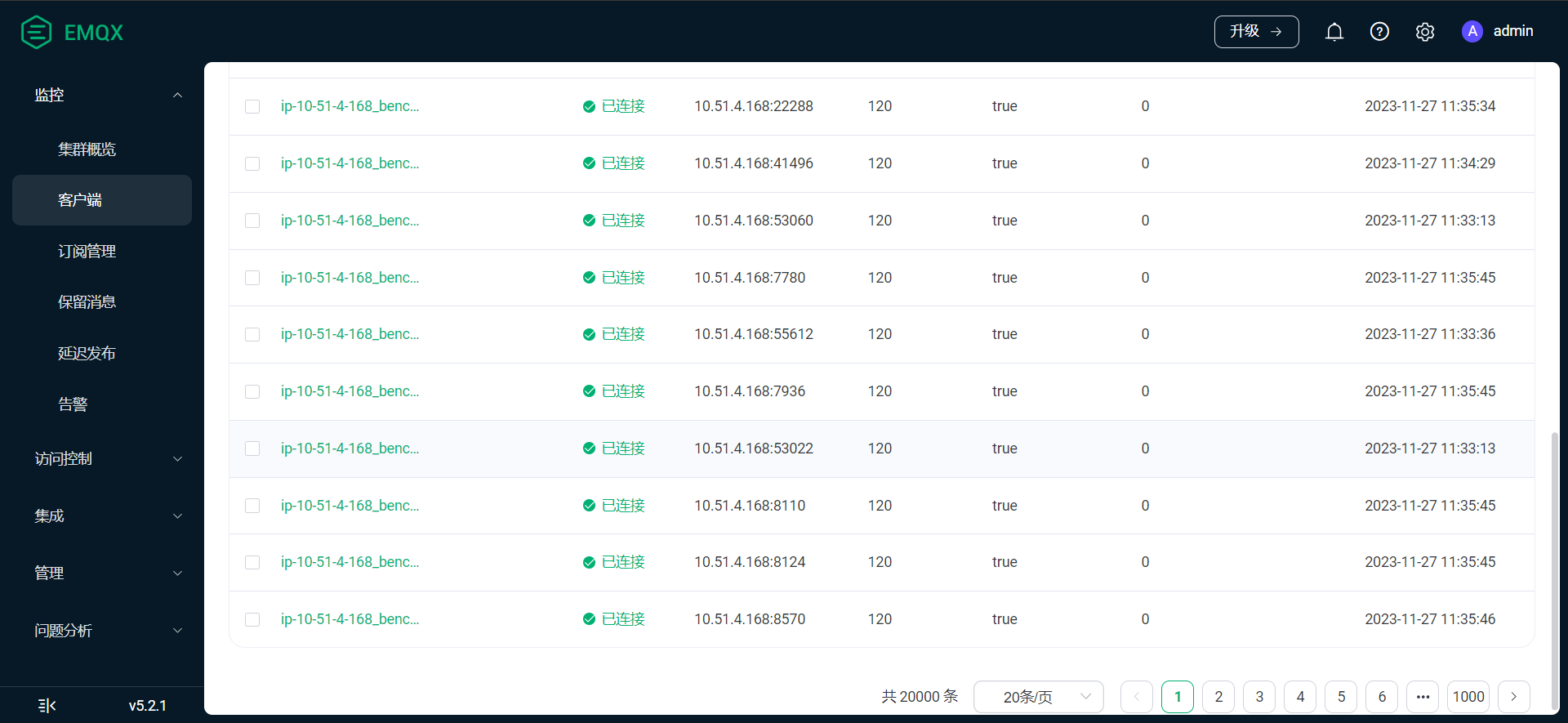
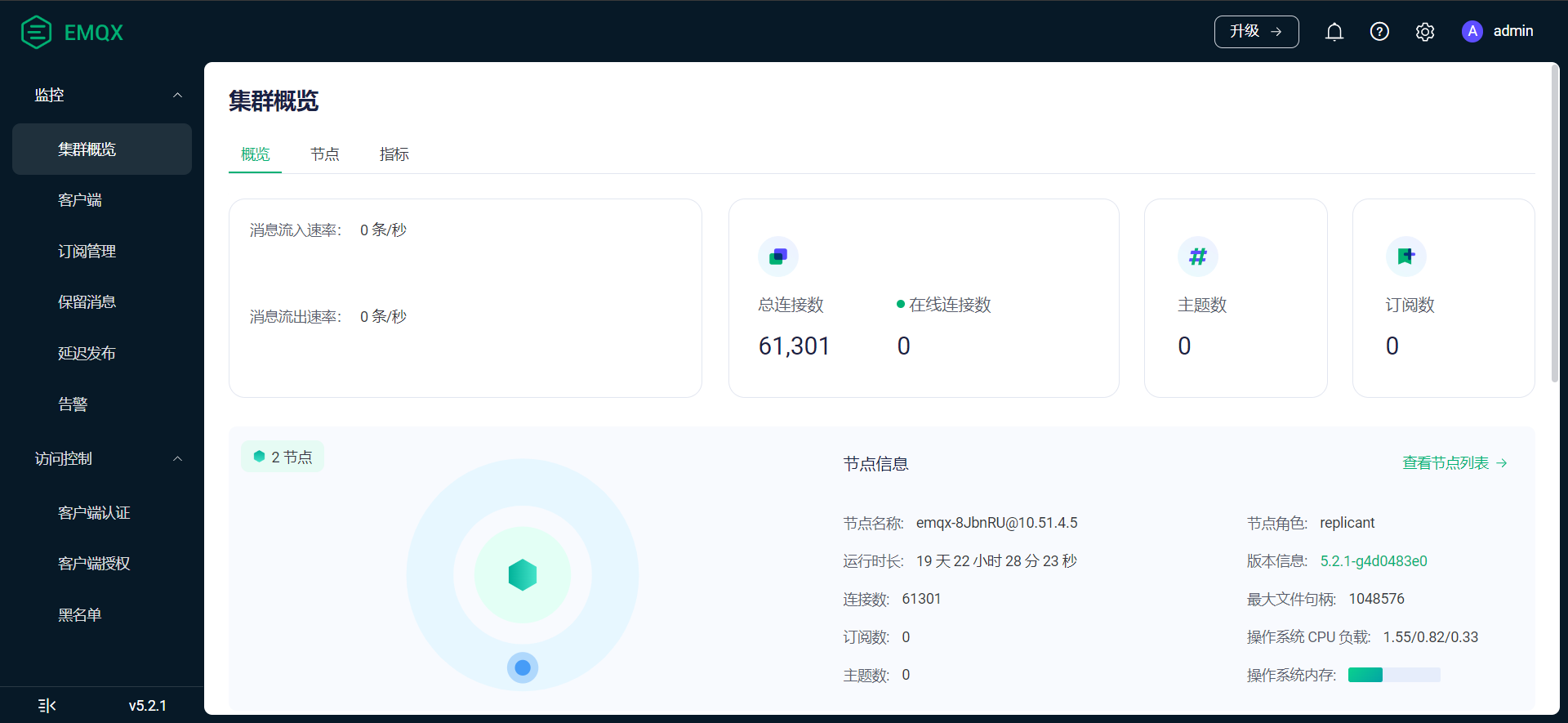
麻烦你随便选一个已连接的客户端点开,来个图看看详情
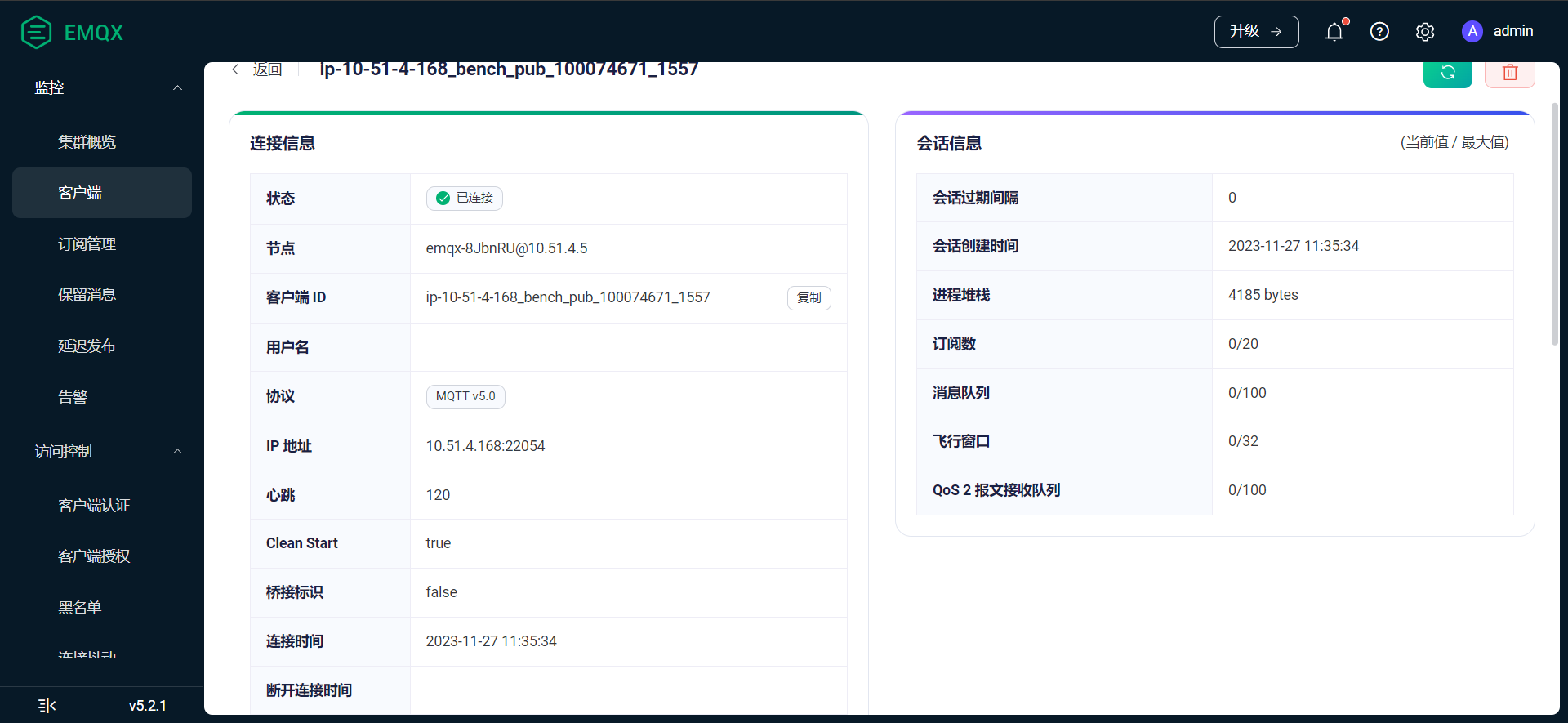
有点奇怪 ![]()
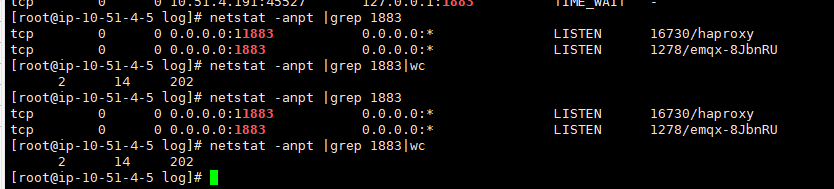
netstat -anpt |grep 1883 |wc
看看网络连接情况。
那方便把这台机器的完整日志上传一下么。感觉他一定受到了什么重伤。。。
2023-11-29T10:01:28.959848+00:00 [error] Generic server mria_node_monitor terminating. Reason: {{badmatch,timeout},[{mria,db_nodes_maybe_rpc,0,[{file,"mria.erl"},{line,656}]},{mria,cluster_nodes,1,[{file,"mria.erl"},{line,169}]},{mria,is_node_in_cluster,1,[{file,"mria.erl"},{line,196}]},{mria,force_leave,1,[{file,"mria.erl"},{line,263}]},{mria_autoclean,'-check/1-lc$^0/1-0-',2,[{file,"mria_autoclean.erl"},{line,40}]},{mria_autoclean,check,1,[{file,"mria_autoclean.erl"},{line,40}]},{mria_node_monitor,handle_info,2,[{file,"mria_node_monitor.erl"},{line,212}]},{gen_server,try_dispatch,4,[{file,"gen_server.erl"},{line,1123}]},{gen_server,handle_msg,6,[{file,"gen_server.erl"},{line,1200}]},{proc_lib,init_p_do_apply,3,[{file,"proc_lib.erl"},{line,240}]}]}. Last message: autoclean. State: {state,[],#Ref<0.2086063485.3237478402.175703>,{autoheal,15000,undefined,undefined,undefined},{autoclean,300000,#Ref<0.2086063485.3237478402.173055>}}.
2023-11-29T10:01:28.960569+00:00 [error] crasher: initial call: mria_node_monitor:init/1, pid: <0.20944.291>, registered_name: mria_node_monitor, error: {{badmatch,timeout},[{mria,db_nodes_maybe_rpc,0,[{file,"mria.erl"},{line,656}]},{mria,cluster_nodes,1,[{file,"mria.erl"},{line,169}]},{mria,is_node_in_cluster,1,[{file,"mria.erl"},{line,196}]},{mria,force_leave,1,[{file,"mria.erl"},{line,263}]},{mria_autoclean,'-check/1-lc$^0/1-0-',2,[{file,"mria_autoclean.erl"},{line,40}]},{mria_autoclean,check,1,[{file,"mria_autoclean.erl"},{line,40}]},{mria_node_monitor,handle_info,2,[{file,"mria_node_monitor.erl"},{line,212}]},{gen_server,try_dispatch,4,[{file,"gen_server.erl"},{line,1123}]},{gen_server,handle_msg,6,[{file,"gen_server.erl"},{line,1200}]},{proc_lib,init_p_do_apply,3,[{file,"proc_lib.erl"},{line,240}]}]}, ancestors: [mria_membership_sup,mria_sup,<0.2169.0>], message_queue_len: 1, messages: [heartbeat], links: [<0.2241.0>,<0.2186.0>], dictionary: [{'$logger_metadata$',#{domain => [mria,node_monitor]}},{rand_seed,{#{jump => #Fun<rand.3.34006561>,max => 288230376151711743,next => #Fun<rand.5.34006561>,type => exsplus},[72137651503071999|267938741373754397]}}], trap_exit: true, status: running, heap_size: 10958, stack_size: 28, reductions: 23912; neighbours: []
2023-11-29T10:01:28.961629+00:00 [error] Supervisor: {local,mria_membership_sup}. Context: child_terminated. Reason: {{badmatch,timeout},[{mria,db_nodes_maybe_rpc,0,[{file,"mria.erl"},{line,656}]},{mria,cluster_nodes,1,[{file,"mria.erl"},{line,169}]},{mria,is_node_in_cluster,1,[{file,"mria.erl"},{line,196}]},{mria,force_leave,1,[{file,"mria.erl"},{line,263}]},{mria_autoclean,'-check/1-lc$^0/1-0-',2,[{file,"mria_autoclean.erl"},{line,40}]},{mria_autoclean,check,1,[{file,"mria_autoclean.erl"},{line,40}]},{mria_node_monitor,handle_info,2,[{file,"mria_node_monitor.erl"},{line,212}]},{gen_server,try_dispatch,4,[{file,"gen_server.erl"},{line,1123}]},{gen_server,handle_msg,6,[{file,"gen_server.erl"},{line,1200}]},{proc_lib,init_p_do_apply,3,[{file,"proc_lib.erl"},{line,240}]}]}. Offender: id=mria_node_monitor,pid=<0.20944.291>.
这个错显示已经是和 core 节点 断开了。
你是用 etcd 给的集群么?
麻烦传一下 etc/emqx.conf的 cluster 配置。
还有分别在 core、replicant 上都 运行一下
emqx_ctl cluster status
感谢
replicant status
[root@ip-10-51-4-5 emqx]# ./bin/emqx_ctl cluster status
Cluster status: #{running_nodes =>
['emqx-8JbnRU@10.51.4.5','emqx-aEfCKq@10.51.3.53'],
stopped_nodes => []}
core status
[root@ip-10-51-3-53 emqx]# ./bin/emqx_ctl cluster status
Cluster status: #{running_nodes =>
['emqx-8JbnRU@10.51.4.5','emqx-aEfCKq@10.51.3.53'],
stopped_nodes => []}
cluster 配置
cluster = {
name = "ap-pro-emqxv5-cls2"
autoheal = true
autoclean = 5m
proto_dist = inet_tcp
discovery_strategy = "etcd"
etcd = {
server = "https://us-dev-etcd.xxx.dev.vpc:12379"
prefix = "ap-pro-emqxv5-cls2"
node_ttl = 1m
}
}
集群是手动建立的,当时把etcd server = "https://us-dev-etcd.xxx.dev.vpc:12379"写错了。就手动加的集群。
你进入了一下未知领域:
不带你这样配置集群的,
使用了 etcd 模式,但是又用命令行手动加集群的。(非常不推荐这么干!)
我们都不敢这么用。
应该是这个原因导致了日志里面一直在 call core rpc 的报错。
了解,搞了个骚操作。
我修改正确后再试试有无问题,感谢。
1 个赞