emqx5.0.23 k8s环境下部署成3+N个节点,在压测环境下由多台虚拟机模拟设备连接对集群进行连接,500w连接只消耗2C左右CPU。但是在线上环境,500w真实设备连接消耗cpu成倍增长,每个节点消耗8C左右cpu。
所以我想查看一下为什么cpu会增加这么多,用什么指令查看呢?
- 压测环境和线上环境的负载是否完全一致,qos/payload_size/规则引擎/桥接都会影响到 CPU。
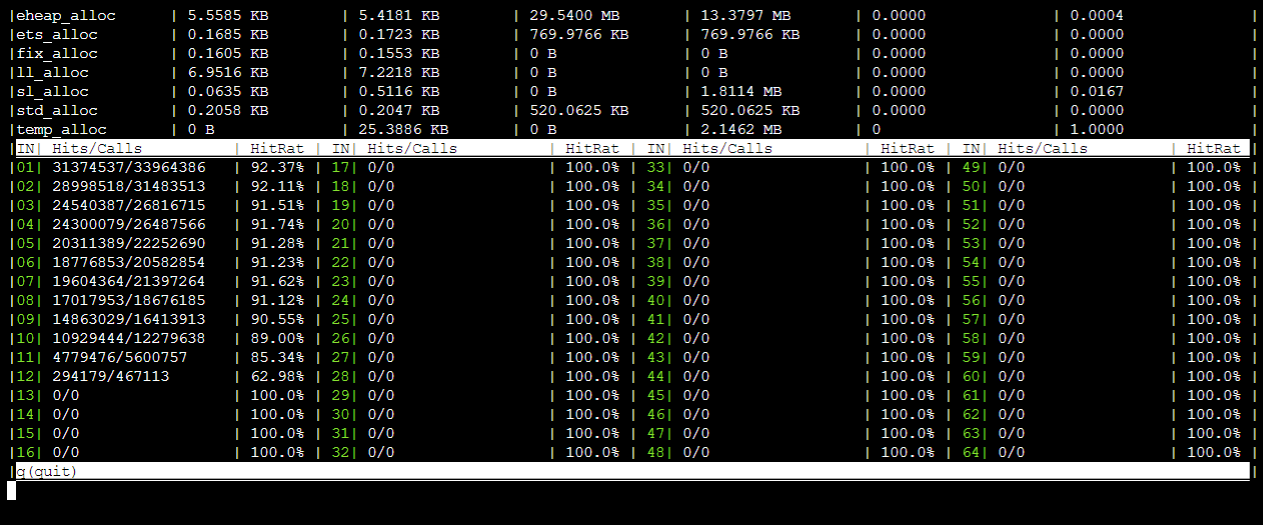
- EMQX 内部资源消耗可以使用命令行接口提供的 observer 工具查看负载,类似于 top 命令
./bin/emqx ctl observer status
主要可以关注 MsgQueue 列有没有过高,以及 Memory 列有没有占用内存过高的进程。



- 连接频繁建立和销毁会有一些额外资源消耗
- qos级别升高也会增加资源使用
- 可以在压测环境全部使用 qos2 消息进行测试,观察资源消耗有没有太大差异
- 发布订阅关系改变也会导致 CPU 占用上升(订阅者变多,单个客户端订阅数变多……)
- 这一点可以在 Dashboard 首页上对比一下两个集群上消息 IO 的速率
- log-level 有没有进行过修改,当前是什么日志级别?大量的日志打印也非常消耗资源。
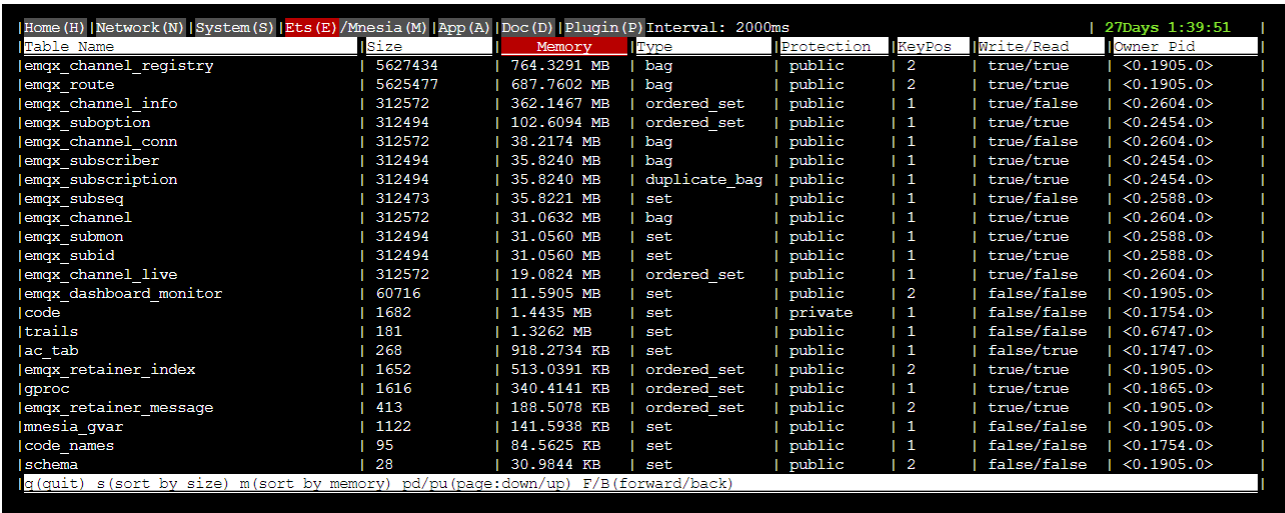
我发现了一个问题,就是单节点上connections只有三十几万,但是topic却有五百万之多(见下图),具体原因我还要再排查下,我猜测是因为设备连接后断开重连到了其他节点,topic被保留。我想请问有没有办法可以查看、清除一些无用的topics呢?我将尝试一下 cluster.autoclean。

Topics 是集群中所有主题的数量(发布者和订阅者可能不在同一节点,所以每个节点都需要一份全量的主题路由信息)
cluster.autoclean 与 topic 无关。 v5.3.0 配置手册 - 集群设置
Subscriptions 才是当前节点的订阅数量
那有能删除topics的指令吗?我怀疑是这个topics太多了导致cpu增长,因为每次都要查询全量topic?
或者说有清理离线连接的指令吗?出现这个现象的原因应该是设备连接后不久断连,导致大量断开的连接信息还保留在集群里,能把这些信息清掉吗?
并没有 “删除 Topics” 的指令,Topics 5842397/5843608 意思是当前所有的客户端一共订阅了 5842397 个主题(过滤器),要降低这个值除非让客户端取消订阅主题。
- Dashboard 的 Clients 页面中,查看具体某个客户端订阅了哪些主题过滤器。
- 压测环境中,客户端会订阅很多主题么?如果差异较大,可以从这个方向来调查。
是这样的连接不止是这个集群里的连接,还有其他的emqx集群,比如说有千万级的连接,但是分到这个集群的只有五百万连接,但是这些连接隔三差五的会断连又重连,但是经过负载均衡后,这些断连的设备他们会连到其他的emqx集群,这样会造成大量断连后的连接信息还存在这个集群里吗?每个连接只会订阅一个topic,压测时不会有这么多连接断连又重连,也没有其他的集群供重连的设备连接,差异点应该在这里。
每个连接只会订阅一个 topic
5842397 如果和当前集群连接数一致的话,和预期是相符的。
大量断连后的连接信息还存在这个集群里吗?
不会。
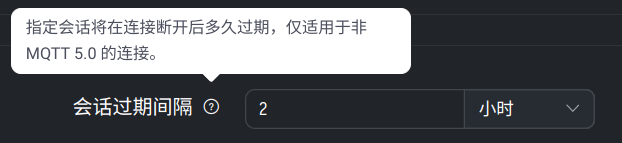
即便是使用 clean_session=false 的连接,在客户端断开,并且会话超期后会被清除
MQTT 配置 → 会话 → 会话过期间隔
我上述描述的场景,会因为promethus造成大量的cpu消耗吗?之前另一个问题里有人回答我用这个方法降低cpu消耗https://github.com/emqx/emqx/issues/11611
这样聊下来 为什么生产cpu比压测高很多的问题还是没找出来
注意到另一个帖子: 出现 large_heap warning日志
[{file,“prometheus_vm_dist_collector.erl”},{line,271}]
会因为 prometheus 造成额外 cpu 消耗的。
压测环境有开启 prometheus 么?
压测没开promethus,有方法能不重启集群关掉promethus吗

我是采用这个方法开启promethus监控的使用 Prometheus+Grafana 监控 EMQX 集群 | EMQX Operator2.1.1 文档
不能直接从dashboard上关掉,是不是可以kubectl delete -f 删除emqx-exporter以停止promethus采集?
只关闭 Prometheus 及 Grafana 即可。
我通过api
curl -X ‘PUT’
‘http://10.42.6.245:18083/api/v5/prometheus’
-H ‘accept: application/json’
-H ‘Authorization: Basic OWU4MGZhOTRhOGE3N2YwNzpFbnNQaW9LeGt1YzRWdTc3czhHcDRIbDlBaE9XMGFEMGw5Q0diaGxPYTlCZjhQ’
-H ‘Content-Type: application/json’
-d ‘{
“enable”: false,
“headers”: {
“header-name”: “header-value”
},
“interval”: “15s”,
“job_name”: “${name}/instance/${name}~${host}”,
“push_gateway_server”: “http://127.0.0.1:9091”
}’
关闭了promethus
cpu还是很高哦
5.0.23 确定会因为pull或push promethues带来CPU使用率飙高。
虽然你关了push,
看你使用了emqx-exporter,他是定时pull emqx的http 接口的。
你需要把他也停了。
我现在设置pull的时间间隔是1分钟。
如果我设置成30分钟呢?按照你的理论是不是每30分钟出现一次突刺 然后下降到正常水平?
没有什么固定的理论,我也不敢说太绝对。每个用户使用的具体场景不一样。
我只是说我们自己在这个版本上压测,这些开关对 CPU 的影响比较大。
如果你想验证的话。建议直接在测试环境上对比着开关了这些值的2种情况,
一测就能明白对你的场景有没有效果。