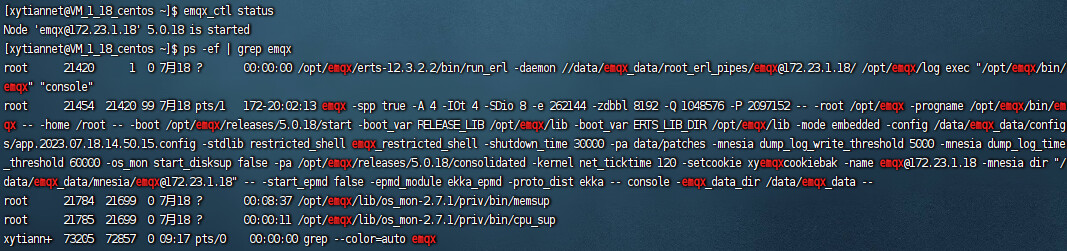
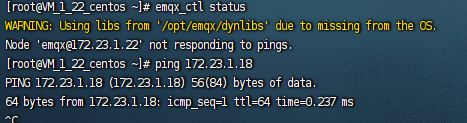
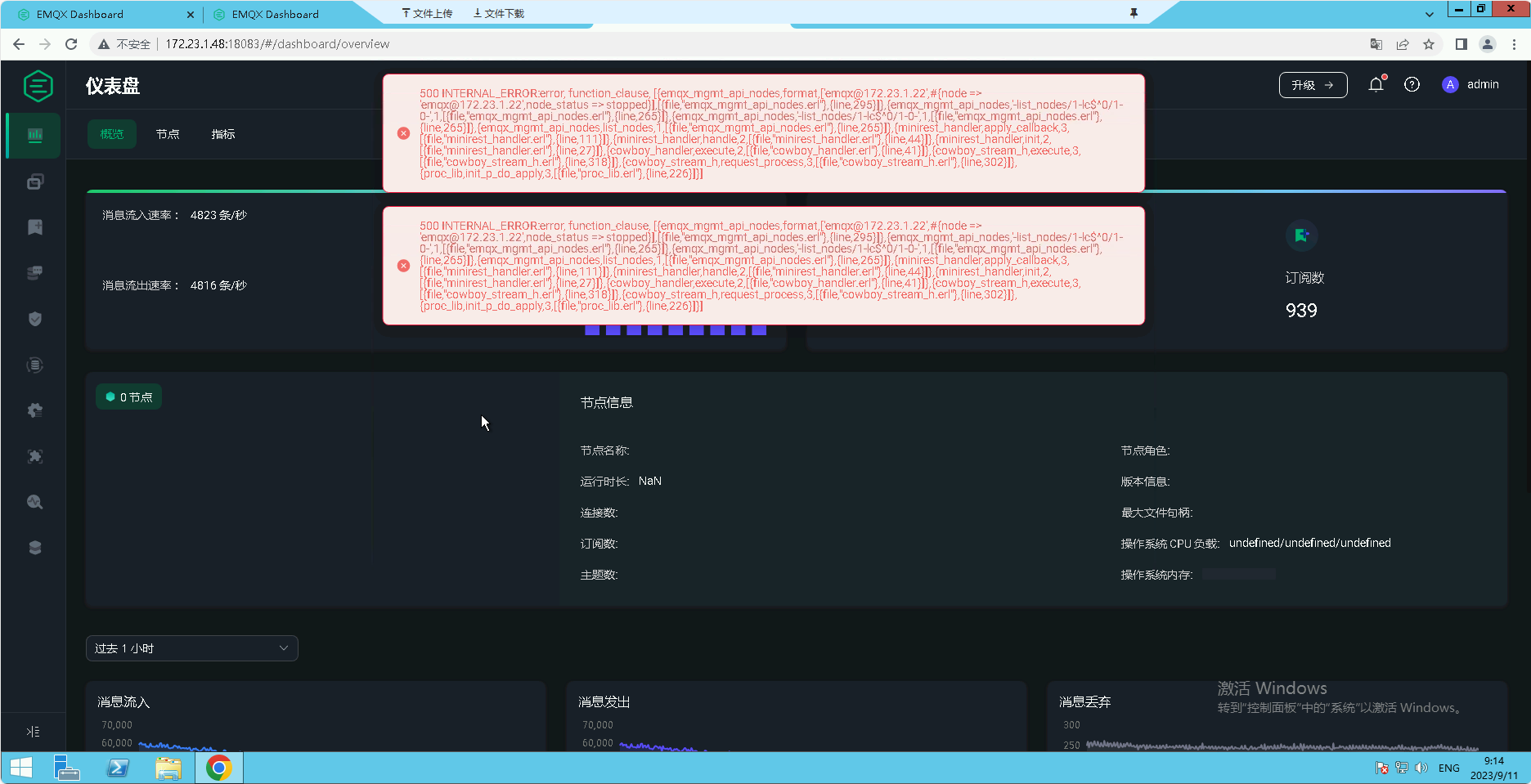
你好,我找到了节点down掉的日志,
其中三个节点的ip分别是:
172.23.1.18,172.23.1.22,172.23.1.48
3-09-11T09:24:02.871939+08:00 [error] Mnesia(‘emqx@172.23.1.22’): ** ERROR ** Mnesia post_commit hook failed: error:badarg, Stacktrace:[{mria_rlog_server,dispatch,3,[{file,“mria_rlog_server.erl”},{line,105}]},{mnesia_hook,do_post_commit,2,[{file,“mnesia_hook.erl”},{line,69}]},{mnesia_tm,do_commit,3,[{file,“mnesia_tm.erl”},{line,1788}]},{mnesia_tm,do_async_dirty,3,[{file,“mnesia_tm.erl”},{line,489}]},{mnesia_tm,doit_loop,1,[{file,“mnesia_tm.erl”},{line,213}]},{mnesia_sp,init_proc,4,[{file,“mnesia_sp.erl”},{line,34}]},{proc_lib,init_p_do_apply,3,[{file,“proc_lib.erl”},{line,226}]}]
2023-09-11T09:24:02.874133+08:00 [error] message=channel_closed driver=tcp socket=“#Port<0.16>” action=stopping
2023-09-11T09:24:02.934165+08:00 [error] Mnesia(‘emqx@172.23.1.22’): ** ERROR ** Mnesia post_commit hook failed: error:badarg, Stacktrace:[{mria_rlog_server,dispatch,3,[{file,“mria_rlog_server.erl”},{line,105}]},{mnesia_hook,do_post_commit,2,[{file,“mnesia_hook.erl”},{line,69}]},{mnesia_tm,do_commit,3,[{file,“mnesia_tm.erl”},{line,1788}]},{mnesia_tm,do_async_dirty,3,[{file,“mnesia_tm.erl”},{line,489}]},{mnesia_tm,doit_loop,1,[{file,“mnesia_tm.erl”},{line,213}]},{mnesia_sp,init_proc,4,[{file,“mnesia_sp.erl”},{line,34}]},{proc_lib,init_p_do_apply,3,[{file,“proc_lib.erl”},{line,226}]}]
2023-09-11T09:24:07.853989+08:00 [error] Mria(Membership): Failed to ping emqx@172.23.1.18