环境
- EMQX 版本:5.0.25
- 操作系统版本: 5.10.178-162.673.amzn2.aarch64
重现此问题的步骤
- 建立3个core,10个replicant
- 缩减成0个replicant节点
- 增加10个replicant节点
预期行为
replicant正常加入集群
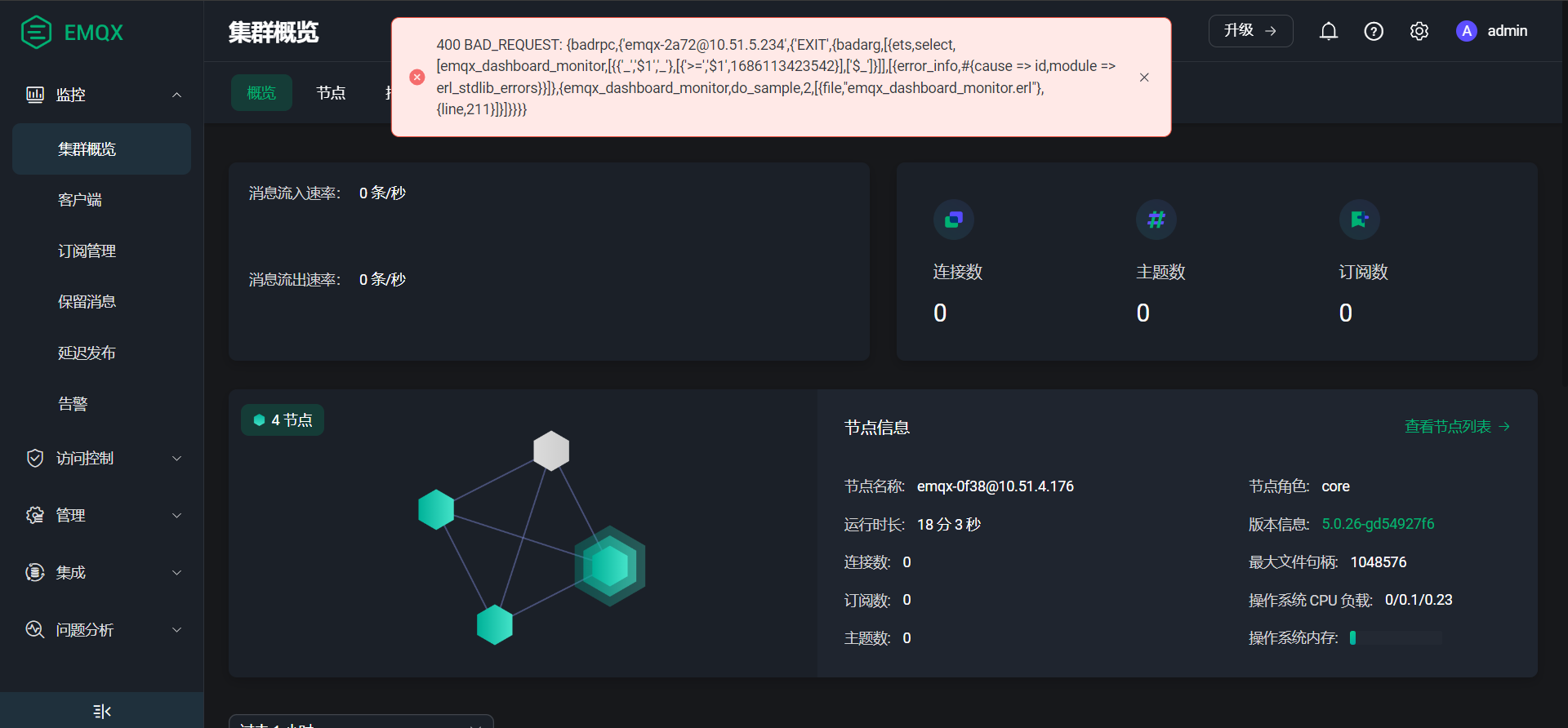
实际行为
2023-05-31T05:59:16.293826+00:00 [warning] msg: Dashboard monitor error, mfa: emqx_dashboard_monitor:current_rate/1, line: 144, reason: {noproc,{gen_server,call,[emqx_dashboard_monitor,current_rate,5000]}}
2023-05-31T05:59:19.284816+00:00 [warning] msg: Dashboard monitor error, mfa: emqx_dashboard_monitor:current_rate/1, line: 144, reason: {noproc,{gen_server,call,[emqx_dashboard_monitor,current_rate,5000]}}
2023-05-31T05:59:22.391515+00:00 [warning] msg: Dashboard monitor error, mfa: emqx_dashboard_monitor:current_rate/1, line: 144, reason: {noproc,{gen_server,call,[emqx_dashboard_monitor,current_rate,5000]}}
2023-05-31T05:59:25.284789+00:00 [warning] msg: Dashboard monitor error, mfa: emqx_dashboard_monitor:current_rate/1, line: 144, reason: {noproc,{gen_server,call,[emqx_dashboard_monitor,current_rate,5000]}}
2023-05-31T05:59:28.299784+00:00 [warning] msg: Dashboard monitor error, mfa: emqx_dashboard_monitor:current_rate/1, line: 144, reason: {noproc,{gen_server,call,[emqx_dashboard_monitor,current_rate,5000]}}
2023-05-31T05:59:31.304818+00:00 [warning] msg: Dashboard monitor error, mfa: emqx_dashboard_monitor:current_rate/1, line: 144, reason: {noproc,{gen_server,call,[emqx_dashboard_monitor,current_rate,5000]}}
2023-05-31T05:59:34.280598+00:00 [warning] msg: Dashboard monitor error, mfa: emqx_dashboard_monitor:current_rate/1, line: 144, reason: {noproc,{gen_server,call,[emqx_dashboard_monitor,current_rate,5000]}}
2023-05-31T05:59:37.280142+00:00 [warning] msg: Dashboard monitor error, mfa: emqx_dashboard_monitor:current_rate/1, line: 144, reason: {noproc,{gen_server,call,[emqx_dashboard_monitor,current_rate,5000]}}
2023-05-31T05:59:40.302780+00:00 [warning] msg: Dashboard monitor error, mfa: emqx_dashboard_monitor:current_rate/1, line: 144, reason: {noproc,{gen_server,call,[emqx_dashboard_monitor,current_rate,5000]}}
2023-05-31T05:59:43.294644+00:00 [warning] msg: Dashboard monitor error, mfa: emqx_dashboard_monitor:current_rate/1, line: 144, reason: {noproc,{gen_server,call,[emqx_dashboard_monitor,current_rate,5000]}}
2023-05-31T05:59:46.291294+00:00 [warning] msg: Dashboard monitor error, mfa: emqx_dashboard_monitor:current_rate/1, line: 144, reason: {noproc,{gen_server,call,[emqx_dashboard_monitor,current_rate,5000]}}
2023-05-31T05:59:49.292347+00:00 [warning] msg: Dashboard monitor error, mfa: emqx_dashboard_monitor:current_rate/1, line: 144, reason: {noproc,{gen_server,call,[emqx_dashboard_monitor,current_rate,5000]}}
2023-05-31T05:59:49.295833+00:00 [error] State machine ‘$mria_meta_shard’ terminating. Reason: {timeout,{gen_server,call,[mria_lb,core_nodes,30000]}}. Stack: [{gen_server,call,3,[{file,“gen_server.erl”},{line,247}]},{mria_rlog_replica,try_connect,2,[{file,“mria_rlog_replica.erl”},{line,378}]},{mria_rlog_replica,handle_reconnect,1,[{file,“mria_rlog_replica.erl”},{line,341}]},{gen_statem,loop_state_callback,11,[{file,“gen_statem.erl”},{line,1205}]},{proc_lib,init_p_do_apply,3,[{file,“proc_lib.erl”},{line,226}]}]. Last event: {state_timeout,reconnect}. State: {disconnected,{d,‘$mria_meta_shard’,<0.1976.0>,undefined,undefined,undefined,0,undefined,undefined,false}}.
2023-05-31T05:59:49.296110+00:00 [error] crasher: initial call: mria_rlog_replica:init/1, pid: <0.1977.0>, registered_name: ‘$mria_meta_shard’, exit: {{timeout,{gen_server,call,[mria_lb,core_nodes,30000]}},[{gen_server,call,3,[{file,“gen_server.erl”},{line,247}]},{mria_rlog_replica,try_connect,2,[{file,“mria_rlog_replica.erl”},{line,378}]},{mria_rlog_replica,handle_reconnect,1,[{file,“mria_rlog_replica.erl”},{line,341}]},{gen_statem,loop_state_callback,11,[{file,“gen_statem.erl”},{line,1205}]},{proc_lib,init_p_do_apply,3,[{file,“proc_lib.erl”},{line,226}]}]}, ancestors: [<0.1976.0>,mria_shards_sup,mria_rlog_sup,mria_sup,<0.1911.0>], message_queue_len: 0, messages: [], links: [<0.1976.0>], dictionary: [{‘$logger_metadata$’,#{domain => [mria,rlog,replica],shard => ‘$mria_meta_shard’}}], trap_exit: true, status: running, heap_size: 10958, stack_size: 28, reductions: 9080; neighbours:
2023-05-31T05:59:49.296525+00:00 [error] Supervisor: {<0.1976.0>,mria_replicant_shard_sup}. Context: child_terminated. Reason: {timeout,{gen_server,call,[mria_lb,core_nodes,30000]}}. Offender: id=replica,pid=<0.1977.0>.
2023-05-31T05:59:49.296693+00:00 [error] Supervisor: {<0.1976.0>,mria_replicant_shard_sup}. Context: shutdown. Reason: reached_max_restart_intensity. Offender: id=replica,pid=<0.1977.0>.
2023-05-31T05:59:49.296821+00:00 [error] Supervisor: {local,mria_shards_sup}. Context: child_terminated. Reason: shutdown. Offender: id=‘$mria_meta_shard’,pid=<0.1976.0>.
2023-05-31T05:59:52.311724+00:00 [warning] msg: Dashboard monitor error, mfa: emqx_dashboard_monitor:current_rate/1, line: 144, reason: {noproc,{gen_server,call,[emqx_dashboard_monitor,current_rate,5000]}}