环境
- EMQX 版本:5.0.17
- 操作系统版本:CentOS Linux release 7.9.2009 (Core)
- 操作系统内核版本:6.1.10-1.el7.elrepo.x86_64
重现此问题的步骤
- docker-compose启动容器
version: "3"
services:
emqx:
image: emqx:5.0.17
container_name: emqx
restart: always
network_mode: "host"
privileged: true
healthcheck:
test: ["CMD", "/opt/emqx/bin/emqx_ctl", "status"]
interval: 5s
timeout: 25s
retries: 5
environment:
"EMQX_NODE__NAME": "emqx-sit-srv1@10.10.108.240"
"EMQX_NODE__COOKIE": "aaaaaaaaaaa"
- docker-compose正常启动容器,状态显示unhealth
预期行为
我认为容器正常启动,状态应该是health而不是unhealthy
实际行为
实际上状态是unhealthy,如上复现步骤2截图
t1ger
2
你好,这里应该是一个 Bug,我们已经安排修复了,目前需要麻烦你先使用 EMQX_NAME 和 EMQX_HOST 这两个环境变量来指定节点名和节点 IP 地址。
然后健康情况,需要使用 HTTP API 来查询:
test: ["CMD", "curl", "'http://localhost:18083/status'"]
记得把 localhost 改成你实际的 EMQX IP 地址
您好,这边使用了新的 HTTP API查询了,EMQX_NAME 和 EMQX_HOST 这个也都改了,目前还是unhealthy状态。
- docker-compose.yml
version: "3"
services:
emqx:
image: emqx:5.0.17
container_name: emqx
restart: always
network_mode: "host"
privileged: true
healthcheck:
#test: ["CMD", "/opt/emqx/bin/emqx_ctl", "status"]
test: ["CMD", "curl", "'http://emqx-xt-srv1.sit.bbb.cn:18083/status'"]
interval: 5s
timeout: 25s
retries: 5
environment:
"EMQX_NAME": "emqx-xt-sit-srv1"
"EMQX_HOST": "emqx-xt-srv1.sit.bbb.cn"
"EMQX_NODE__NAME": "emqx-xt-sit-srv1@emqx-xt-srv1.sit.bbb.cn"
"EMQX_NODE__COOKIE": "xtsitsecretcookie"
"EMQX_ALLOW_ANONYMOUS": "false"
"EMQX_BROKER__SHARED_SUBSCRIPTION_STRATEGY": "hash_clientid"
volumes:
- "/data/emqx/etc/emqx.conf:/opt/emqx/etc/emqx.conf:rw"
- "/data/emqx/etc/acl.conf:/opt/emqx/etc/acl.conf:rw"
- "/data/emqx/data:/opt/emqx/data:Z"
- "/data/emqx/log:/opt/emqx/log:Z"
``
2. 启动状态
```shell
[root@kube-sit-master-srv1 docker-compose]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0dcecdac7333 emqx:5.0.17 "/usr/bin/docker-ent…" 46 seconds ago Up 45 seconds (unhealthy) emqx
只要确认这个unhealthy 不是因为某些原因导致集群存在问题就可以了,我可以先注释掉健康检查这部分配置,等你们bug修复!
另外,请问一下,新版本的采用了新的架构后,集群文档如下:
https://www.emqx.io/docs/zh/v5.0/deploy/cluster/mria-introduction.html#mria-rlog-%E6%9E%B6%E6%9E%84%E4%BB%8B%E7%BB%8D
如果我要用新架构,设置 core节点和复制节点,那么 文档中说 《可以通过设置 emqx.conf 中的 node.db_role 参数或 EMQX_NODE__DB_ROLE 环境变量,将某个节点设置为复制节点,同时设置 cluster.core_nodes 指定需要连接到的核心节点。》这个地方 emqx.conf 配置文件里 cluster.core_nodes 参数要怎么配置? 我这边按照我的理解写了配置,您帮忙看看对不对,如果不对,烦请您给个正确的配置
vi emqx.conf
...
cluster {
name = emqxcl
discovery_strategy = manual
cluster.core_nodes = ['emqx-xt-sit-srv1@emqx-xt-srv1.sit.bbb.cn', 'emqx-xt-sit-srv2@emqx-xt-srv2.sit.bbb.cn', 'emqx-xt-sit-srv3@emqx-xt-srv3.sit.bbb.cn']
}
是以上这样的配置吗?
然后用了新的架构后,是core节点来负责写数据,复制节点同步数据,那也就是说 对外让客户端连接后进行写操作的的只有core节点,复制节点只是用于到core节点复制数据,然后供客户端读?
t1ger
5
你的配置是正确的,不过现在只有在手动集群时需要配置这个 core_nodes,如果你使用了 dns 这些集群自动发现策略的话,core_nodes 就不需要配置了,EMQX 会自动判断节点类型。
目前我是手动集群,然后手动去进行配置的。
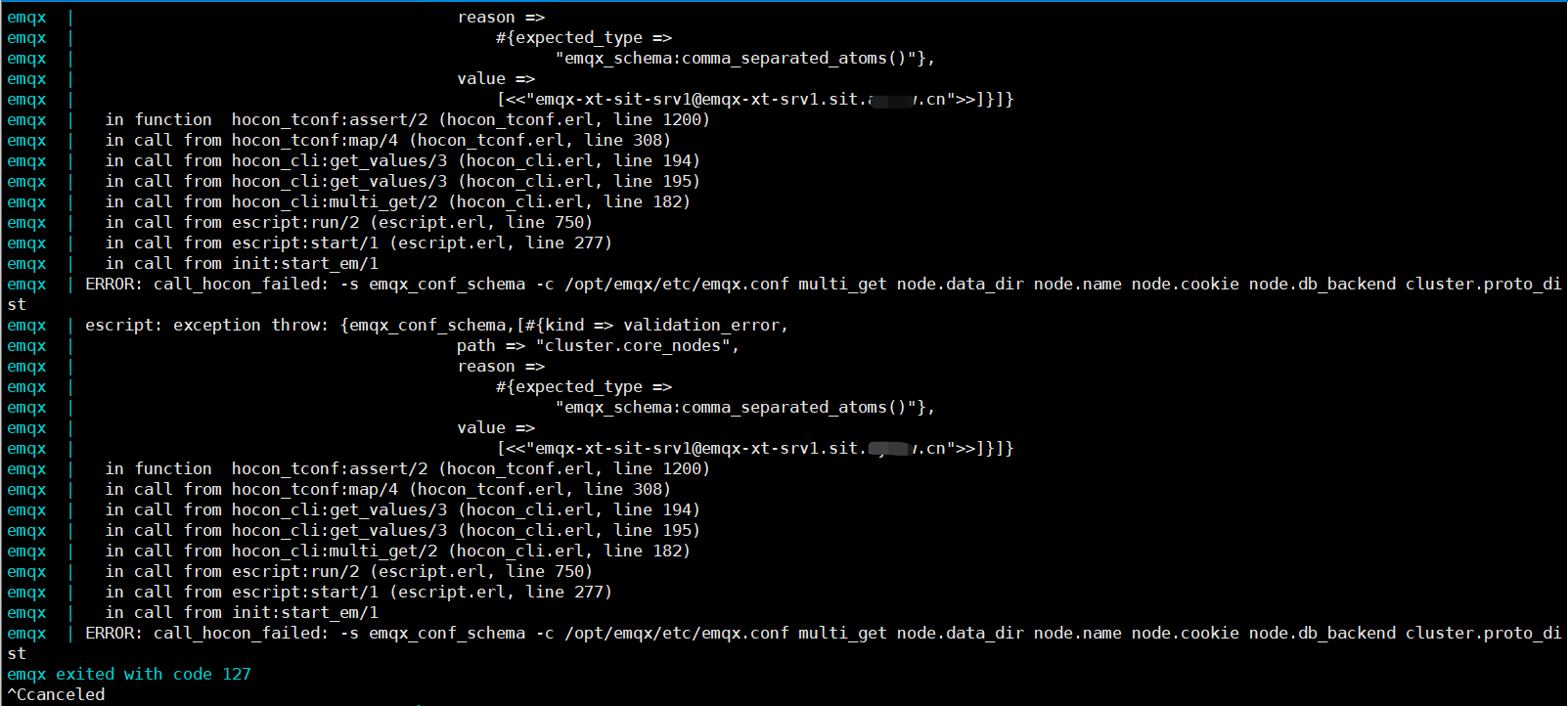
但是我配置了以后,启动服务提示我有错误
emqx.conf 34 行
我尝试设置为以下方式也不行
cluster {
name = emqxcl
discovery_strategy = manual
core_nodes = ['emqx-xt-srv1.sit.bbb.cn']
}
请问还有哪里配置错了或者是缺少了配置参数?
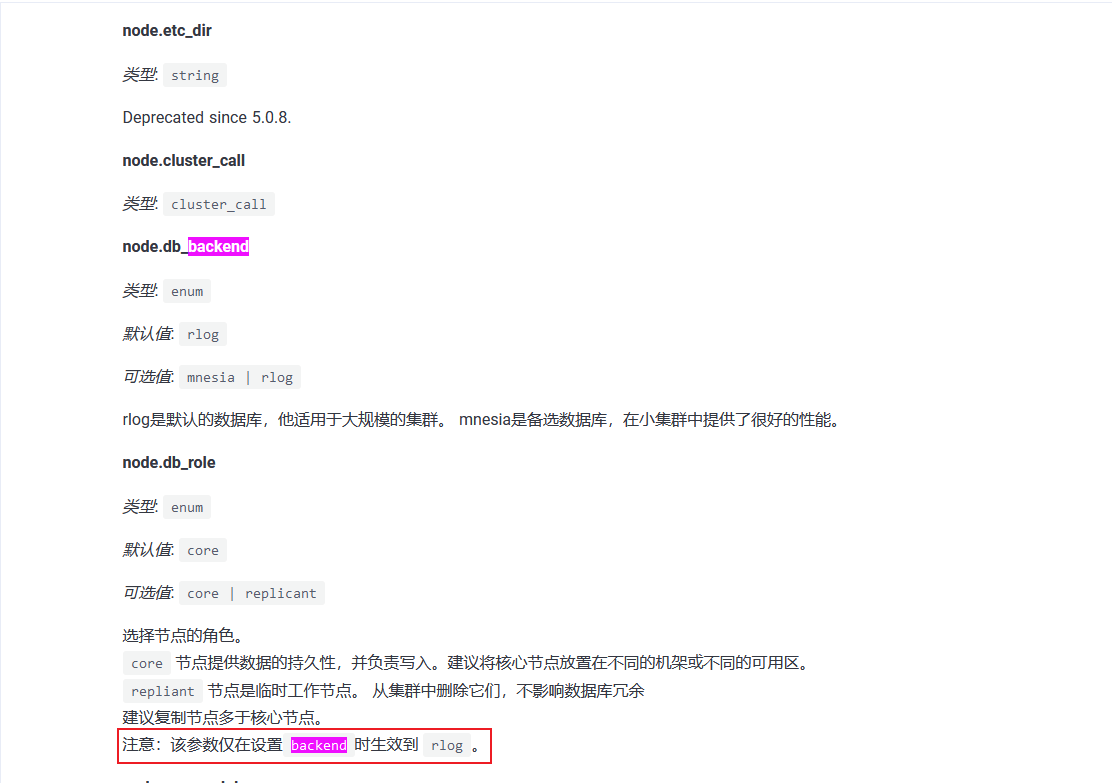
我有看到集群文档中说明:https://www.emqx.io/docs/zh/v5.0/configuration/configuration-manual.html#节点设置
<<注意:该参数仅在设置backend时生效到 rlog。>>,这部分是配置 “node.db_backend” 参数吗?或者不配置,保留默认可以吗?
感觉文档中没有新架构的部署demo,还是不太好配置起来集群。麻烦指导一下呢,感谢!
t1ger
7
core_nodes 中的节点名应该用双引号包含。
我改成了用双引号包含也不可以,出现同样的报错,如下:
配置文件如下
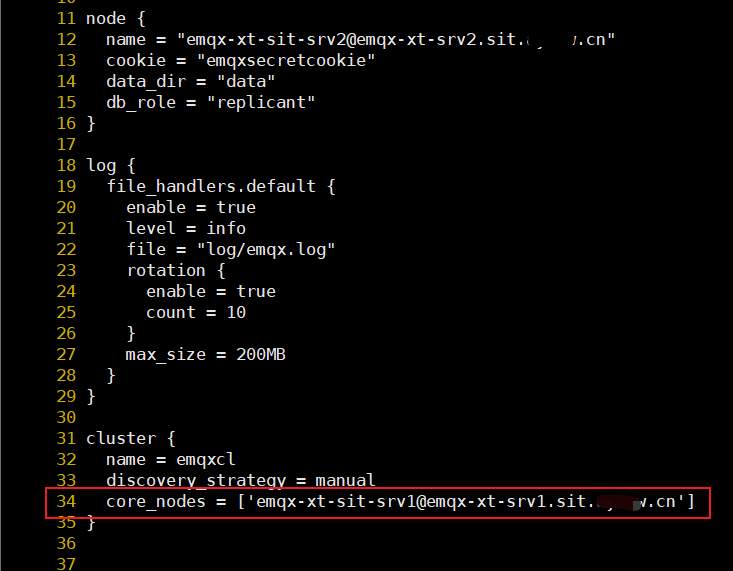
node {
name = "emqx-xt-sit-srv3@emqx-xt-srv3.sit.bbb.cn"
cookie = "emqxsecretcookie"
data_dir = "data"
db_role = "replicant"
}
log {
file_handlers.default {
enable = true
level = info
file = "log/emqx.log"
rotation {
enable = true
count = 10
}
max_size = 200MB
}
}
cluster {
name = emqxcl
discovery_strategy = manual
core_nodes = ["emqx-xt-sit-srv1@emqx-xt-srv1.sit.bbb.cn"]
}
...
以上不行。接着改成下面方式:
配置文件如下
node {
name = "emqx-xt-sit-srv3@emqx-xt-srv3.sit.bbb.cn"
cookie = "emqxsecretcookie"
data_dir = "data"
db_role = "replicant"
}
log {
file_handlers.default {
enable = true
level = info
file = "log/emqx.log"
rotation {
enable = true
count = 10
}
max_size = 200MB
}
}
cluster {
name = emqxcl
discovery_strategy = manual
core_nodes = ["emqx-xt-srv1.sit.bbb.cn"]
}
...
发现也还是不行。还麻烦帮忙指导下问题出现在哪里,看这个错误日志不知道具体原因。
t1ger
9
抱歉,配置成 "emqx-xt-sit-srv1@emqx-xt-srv1.sit.bbb.cn" 这样就好了,不需要两边的 [],这里文档的描述不对,我跟技术确认下然后尽快调整。
-
单个core节点配置成 "emqx-xt-sit-srv1@emqx-xt-srv1.sit.bbb.cn" 是有效的,容器能正常启动,
-
然后我尝试了一下两个core节点的情况下,配置成 "emqx-xt-sit-srv1@emqx-xt-srv1.sit.bbb.cn,emqx-xt-sit-srv2@emqx-xt-srv2.sit.bbb.cn" 以后,也可以正常启动。然后我就在 replicant 节点配置了两个core节点然后启动,看到启动正常。
-
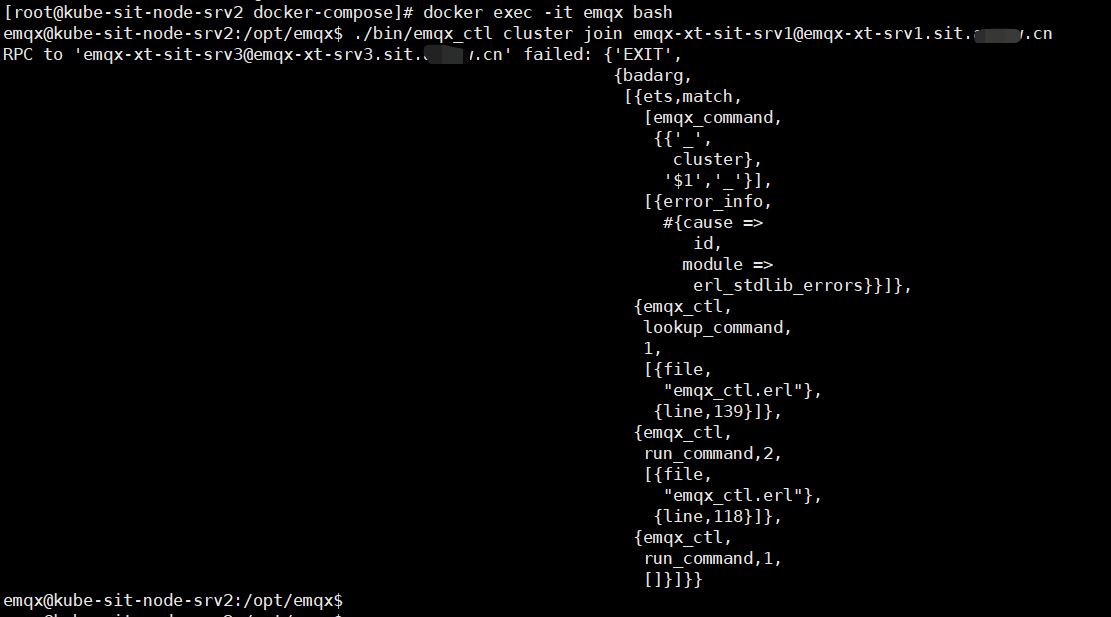
此时,我进入第二个 core节点的容器执行 ./bin/emqx_ctl cluster join emqx-xt-sit-srv1@emqx-xt-srv1.sit.bbb.cn 命令 加入第一个节点组成集群,是可以正常加入集群的。
-
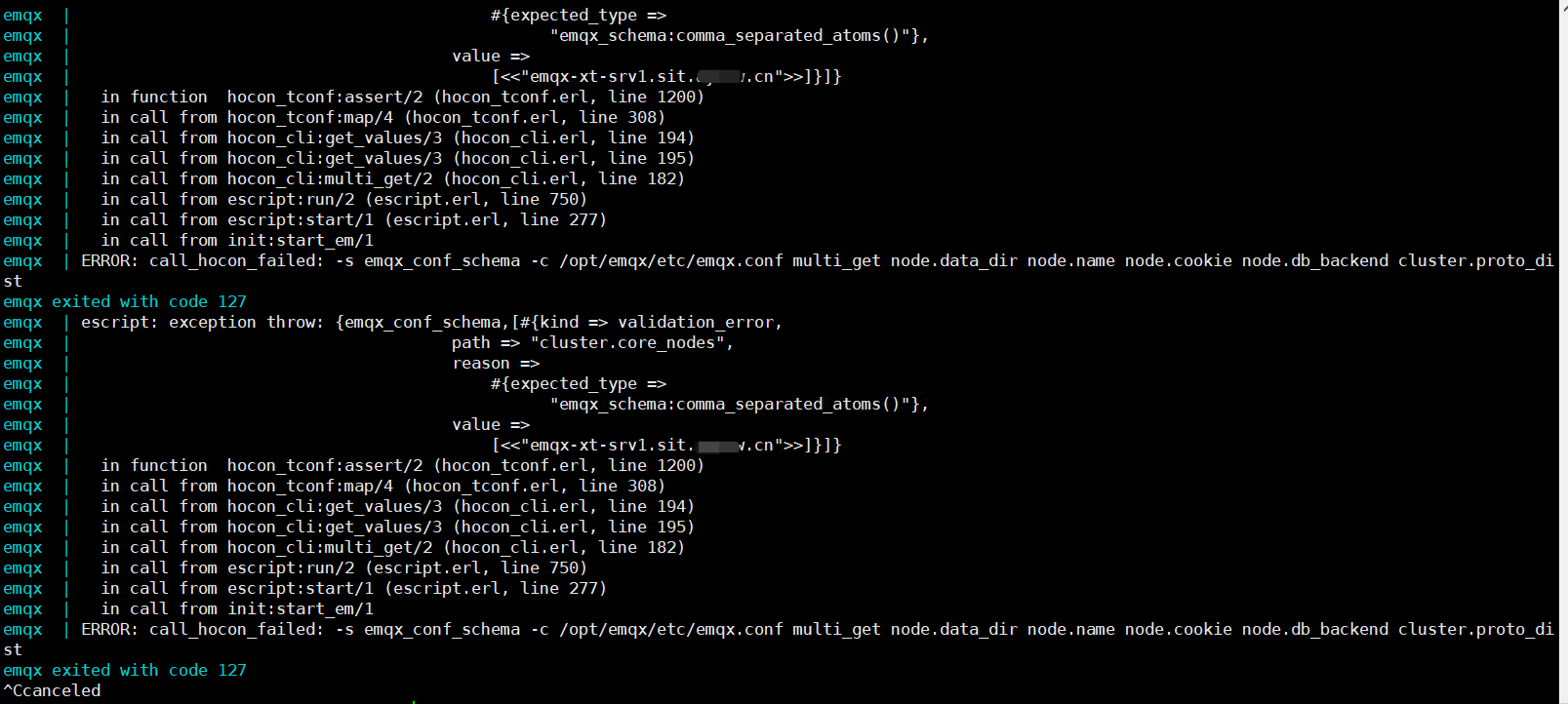
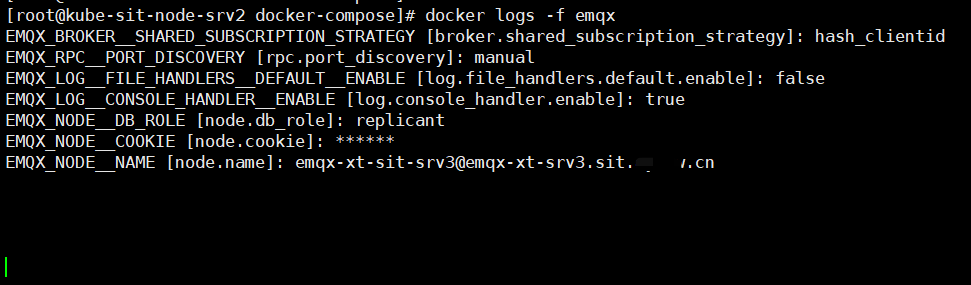
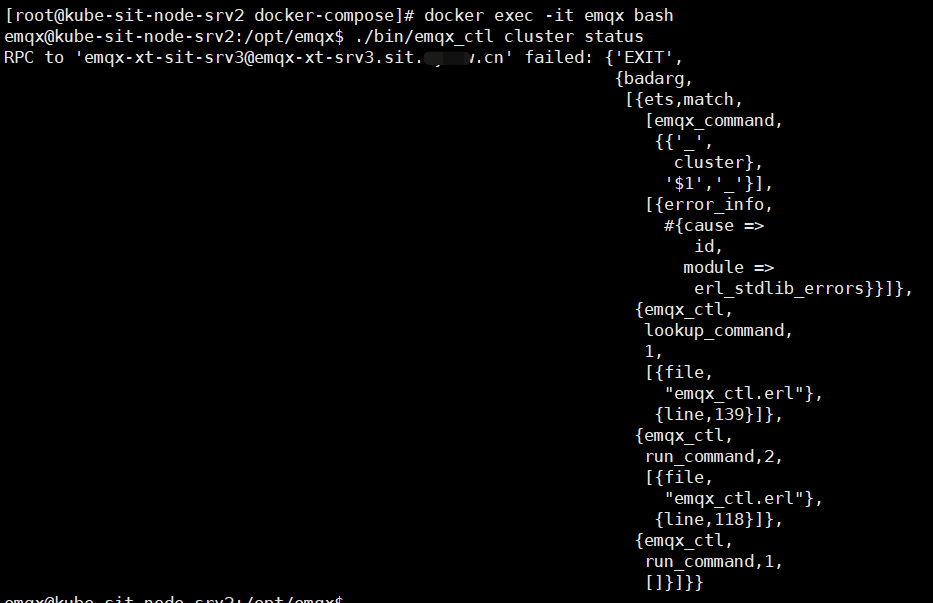
但是当我进入 replicant 节点的容器,查看集群状态,就报错了,截图如下:
或者我执行 ./bin/emqx_ctl cluster join emqx-xt-sit-srv1@emqx-xt-srv1.sit.bbb.cn 以后也报错了。
报错如下:
是不是用了新的架构之后,只需要core节点使用 join 命令加入集群,而 replicant 节点由于指定了 core_nodes 参数指向了core节点,因此不需要在 replicant 节点 执行 join 命令加入集群呢?如果是这样的话,怎么知道 replicant 节点 是否在正常工作呢?或者是因为我哪里没配置对的话,那么应该还需要我这边如何配置?
这些官网上都没说明,所以遇到问题比较多,还请见谅并提供下帮助,谢谢!
t1ger
11
方便的话你可以先直接配置成静态集群,手动集群这个可能有些问题,我去询问下技术团队,我们也尽快完善相关的文档。
那我请问下,如果我这边用您说的静态集群的方式,那我使用 5.0.17 版本的镜像,有5个节点都设置为 core 节点 ,前面用一个LB来做代理组成集群,是这样的意思吗?
t1ger
13
这只是指集群发现的方式,静态集群是指你提前指定好集群内所有节点的节点名。不影响你集群内部署几个节点和是否使用 LB。
你可以参考下这个文档:创建与管理集群 | EMQX 5.0 文档