环境
- EMQX 版本:4.4.11
- 操作系统版本:Centos7.9 ,虚拟机上 zip 安装方式启动
重现此问题的步骤
- 两台虚拟机+Haproxy 部署,配置如下(参考与官方配置,截取部分),集群部署好之后,管理端登录正常
##----------------------------------------------------------------
## global 2021/04/05
##----------------------------------------------------------------
global
log stdout format raw daemon debug
# Replace 1024000 with deployment connections
maxconn 102400
nbproc 1
nbthread 2
cpu-map auto:1/1-2 0-1
tune.ssl.default-dh-param 2048
ssl-default-bind-ciphers ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:ECDHE-RSA-DES-CBC3-SHA:ECDHE-ECDSA-DES-CBC3-SHA:EDH-RSA-DES-CBC3-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:DES-CBC3-SHA:HIGH:SEED:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!RSAPSK:!aDH:!aECDH:!EDH-DSS-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA:!SRP
# Enable the HAProxy Runtime API
# e.g. echo "show table emqx_tcp_back" | sudo socat stdio tcp4-connect:172.100.239.4:9999
stats socket :9999 level admin expose-fd listeners
##----------------------------------------------------------------
## defaults
##----------------------------------------------------------------
defaults
log global
mode tcp
option tcplog
# Replace 1024000 with deployment connections
maxconn 102400
timeout connect 30000
timeout client 600s
timeout server 600s
##----------------------------------------------------------------
## API
##----------------------------------------------------------------
frontend emqx_mgmt
mode tcp
option tcplog
bind *:28083
default_backend emqx_mgmt_back
frontend emqx_dashboard
mode tcp
option tcplog
bind *:28083
default_backend emqx_dashboard_back
backend emqx_mgmt_back
mode http
# balance static-rr
server emqx1 192.168.181.83:18083
server emqx2 192.168.181.190:18083
backend emqx_dashboard_back
mode http
# balance static-rr
server emqx1 192.168.181.83:18083
server emqx2 192.168.181.190:18083
##----------------------------------------------------------------
## public
##----------------------------------------------------------------
frontend emqx_tcp
mode tcp
option tcplog
bind *:2883
# Reject connections that have an invalid MQTT packet
# tcp-request content reject unless { req.payload(0,0), mqtt_is_valid }
default_backend emqx_tcp_back
backend emqx_tcp_back
mode tcp
# Create a stick table for session persistence
stick-table type string len 32 size 100k expire 30m
# Use ClientID / client_identifier as persistence key
stick on req.payload(0,0),mqtt_field_value(connect,client_identifier)
server emqx1 192.168.181.83:1883 check-send-proxy send-proxy-v2
server emqx2 192.168.181.190:1883 check-send-proxy send-proxy-v2
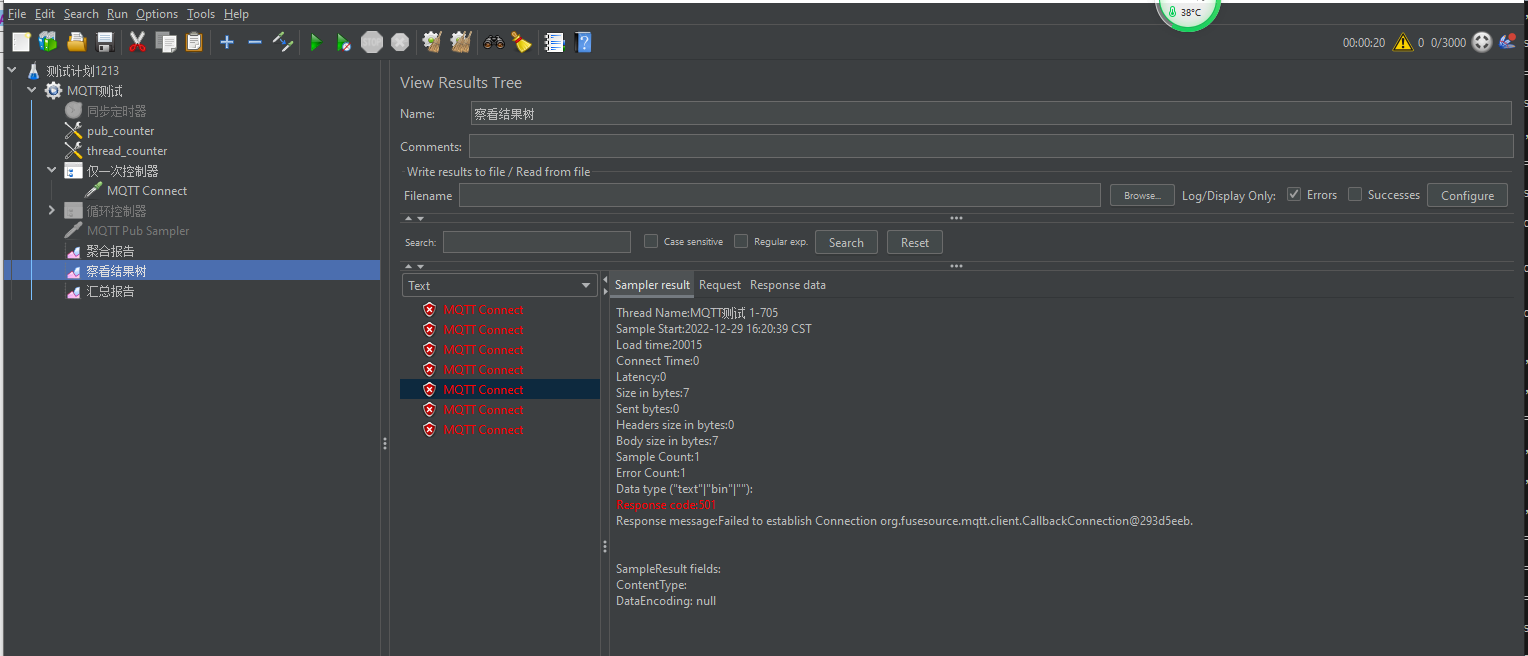
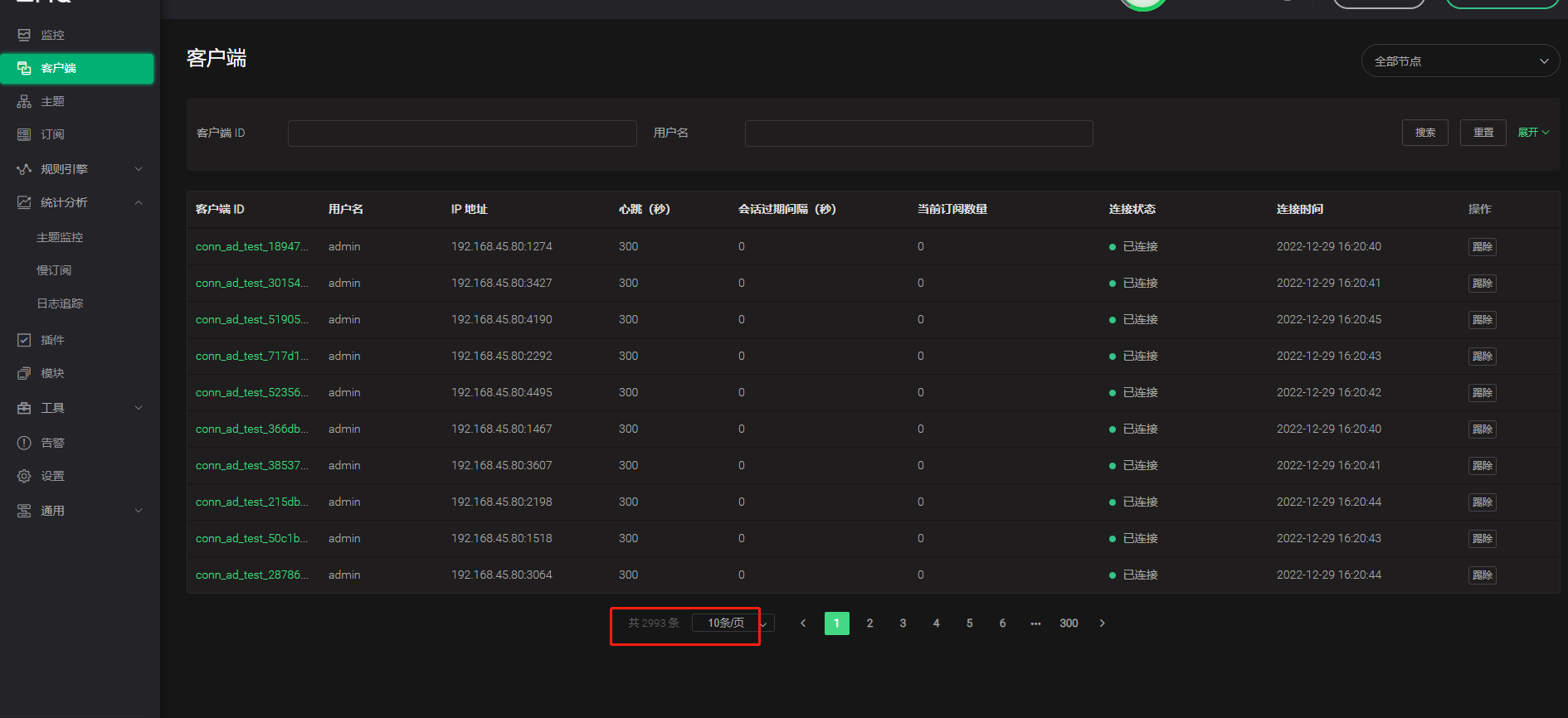
- MQTTX 进行连接测试,第一次连不上,再次点击连接可成功,断开后又连接不上(135连接不上,246可以连接上),能连上的都集中在节点2
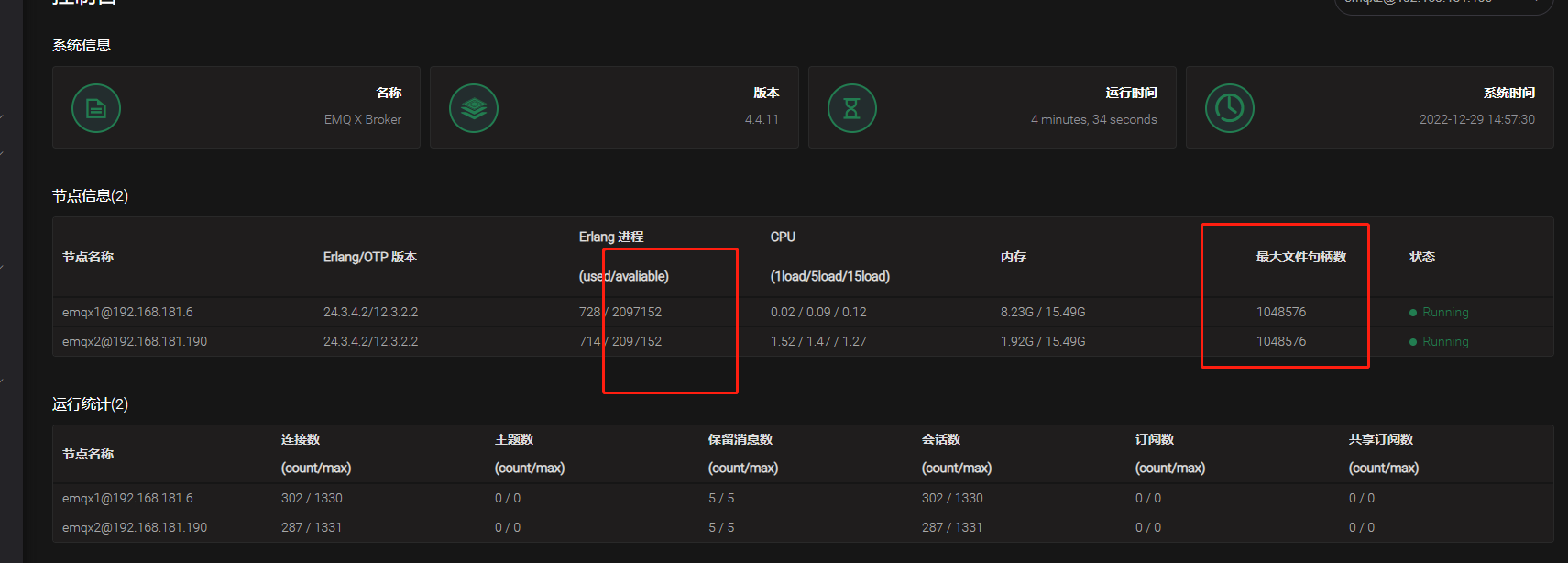
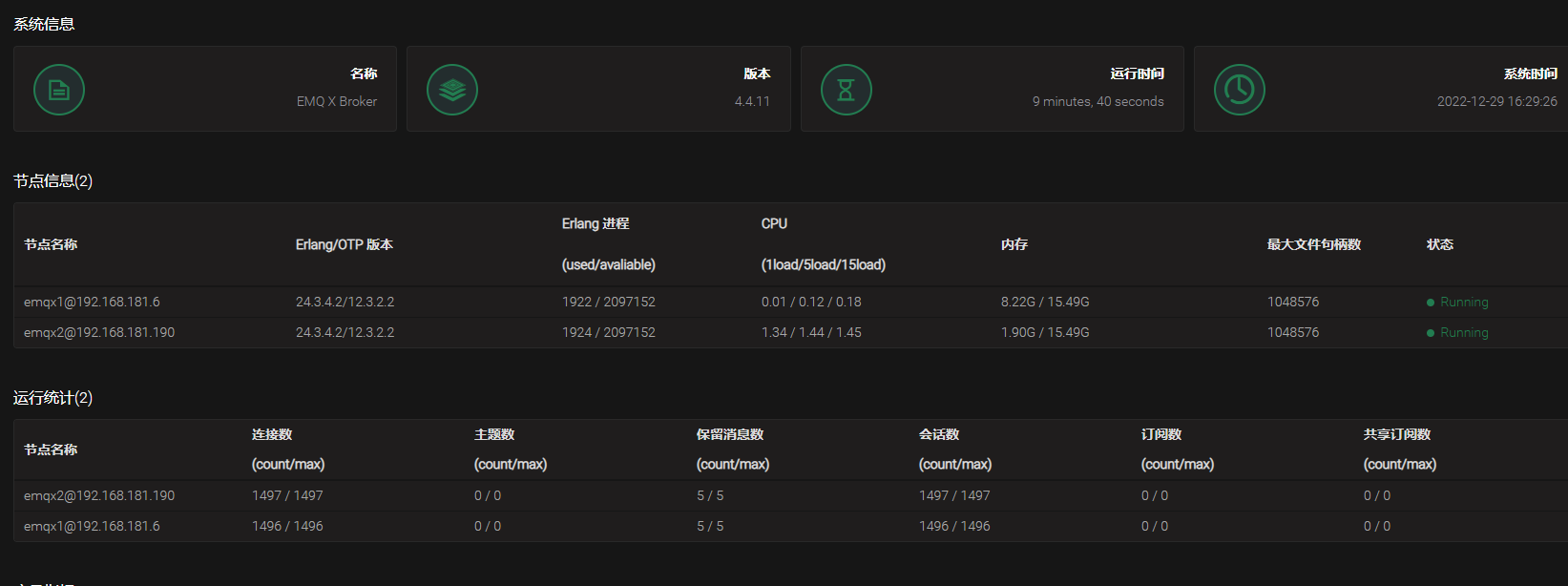
- 节点情况:(无相关连接错误日志)
- 节点1:
+节点2:


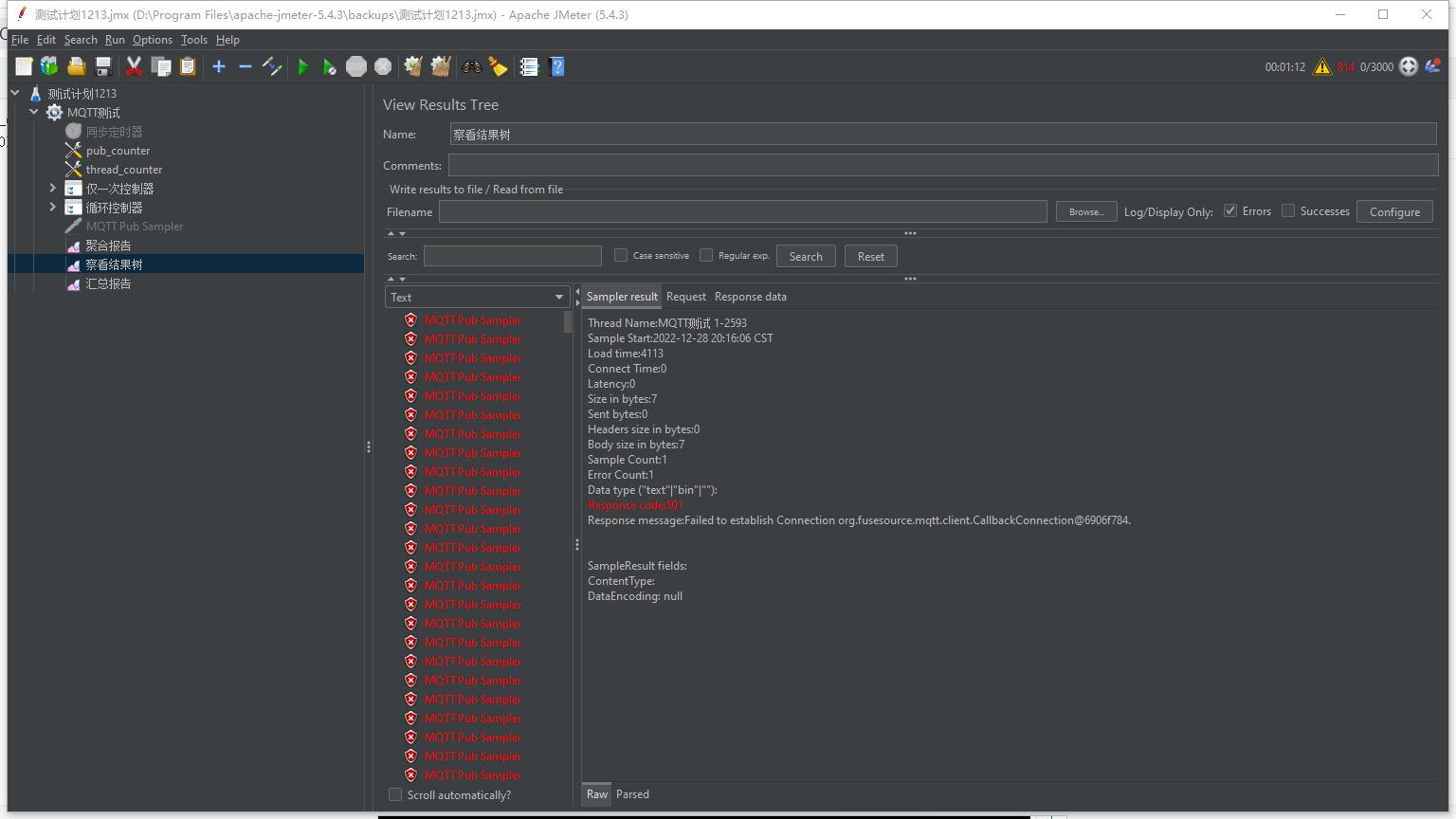
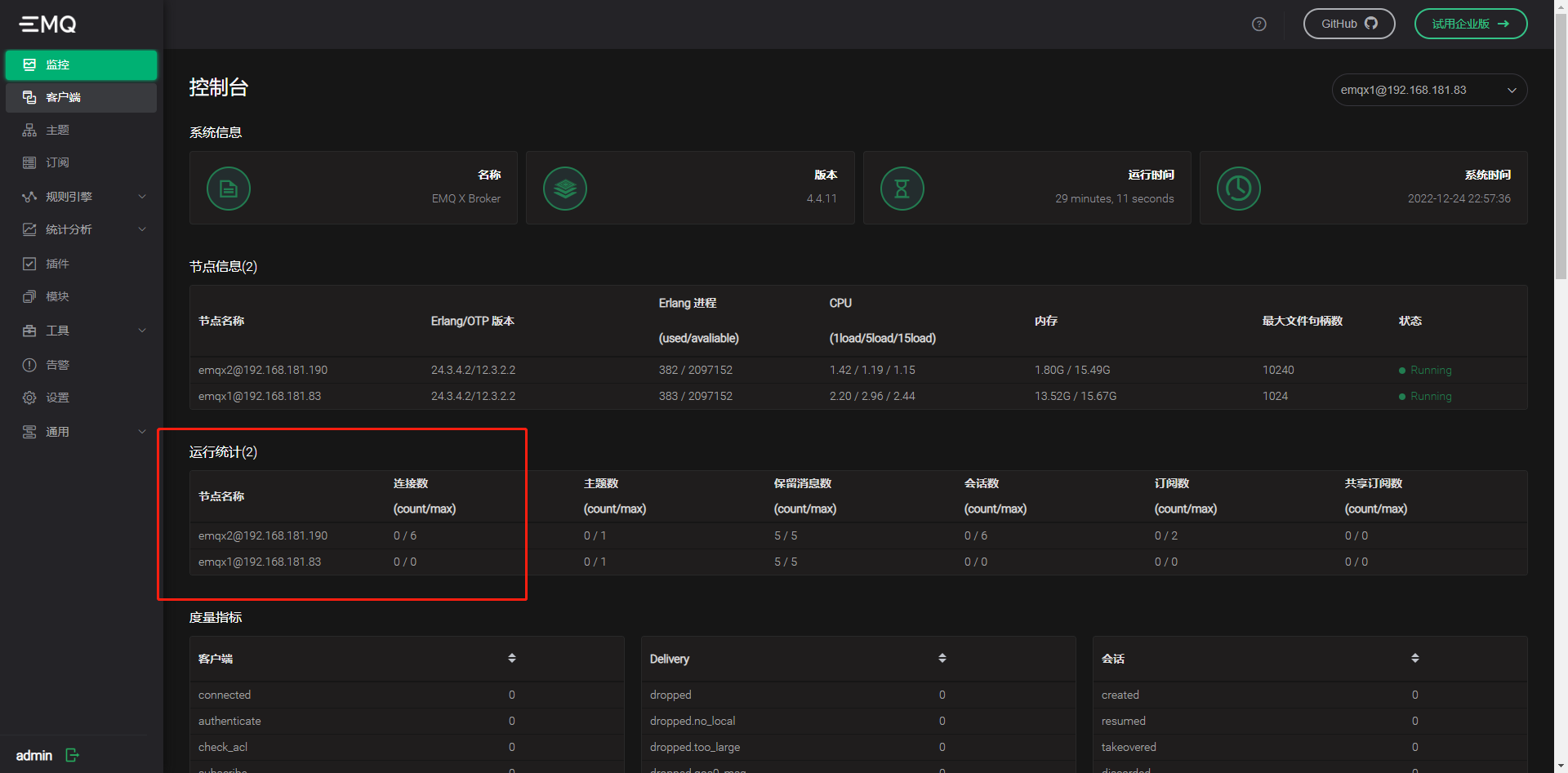
3. 测试连接半个小时左右,集群出现异常,连接不上,查看后有一个节点变成未启动了,还在的那台查看集群状态变成只有一个了,stop 那边为空,管理端也登不上,返回错误501
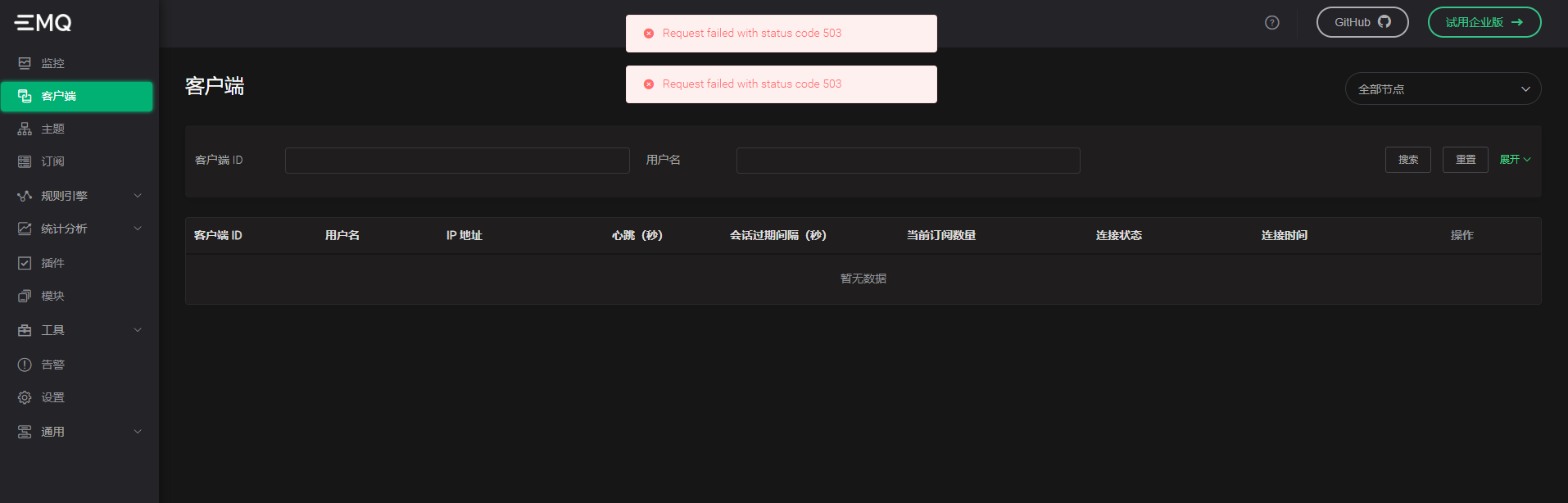
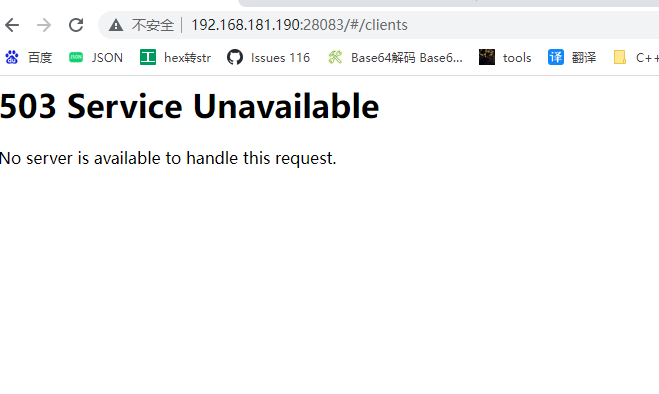
- 节点情况:(集群异常无相关日志)
- 节点1:

+节点2:
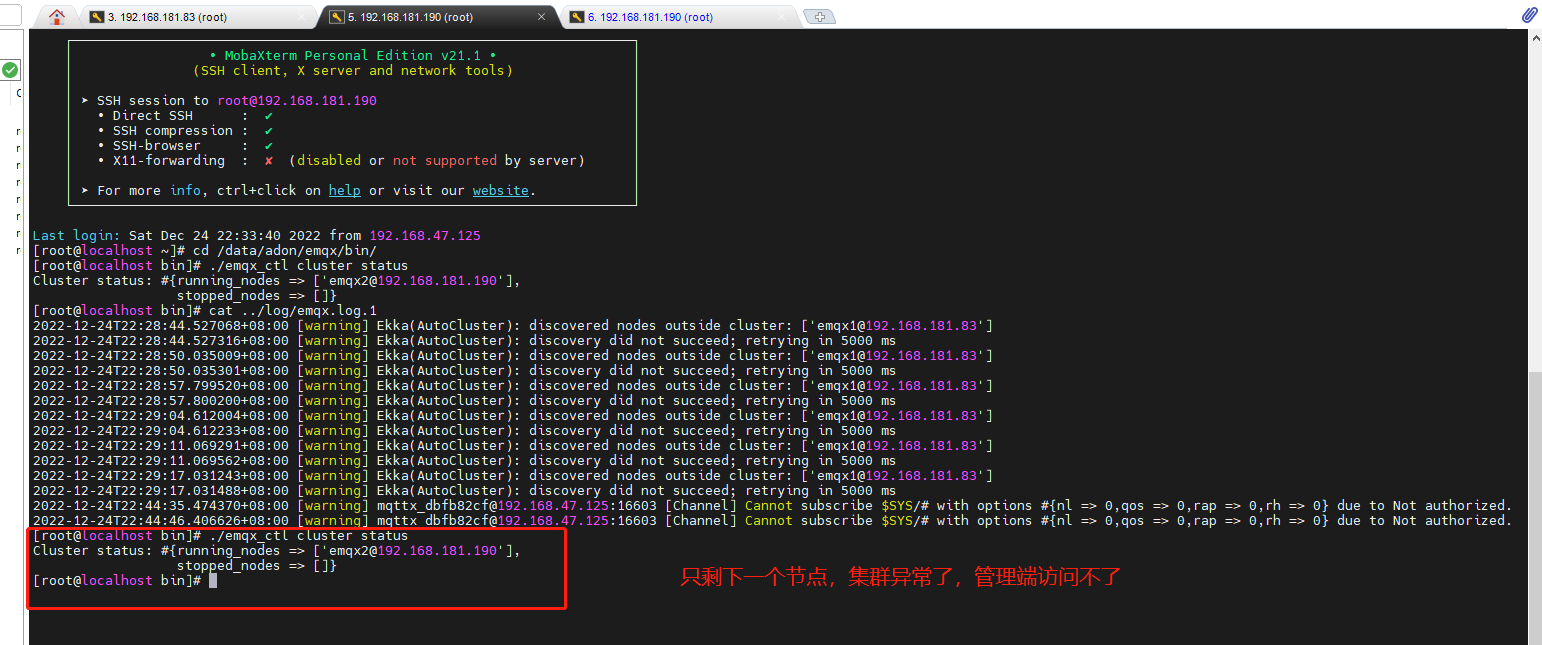
问题
- 135 连接失败,246成功这个是否配置哪里写的不对呢?我看emq日志处无相关连接失败的错误
- 在一段时间之后,节点1会因为连接不上而导致中断?日志我看了也没有报错,集群异常只能重启两个节点,这个是否和问题1有关系?