环境信息
- EMQX 版本:https://github.com/emqx/emqx-rel/tree/v4.2.14
- 操作系统及版本:CentOS 7.9
- 其他
问题描述
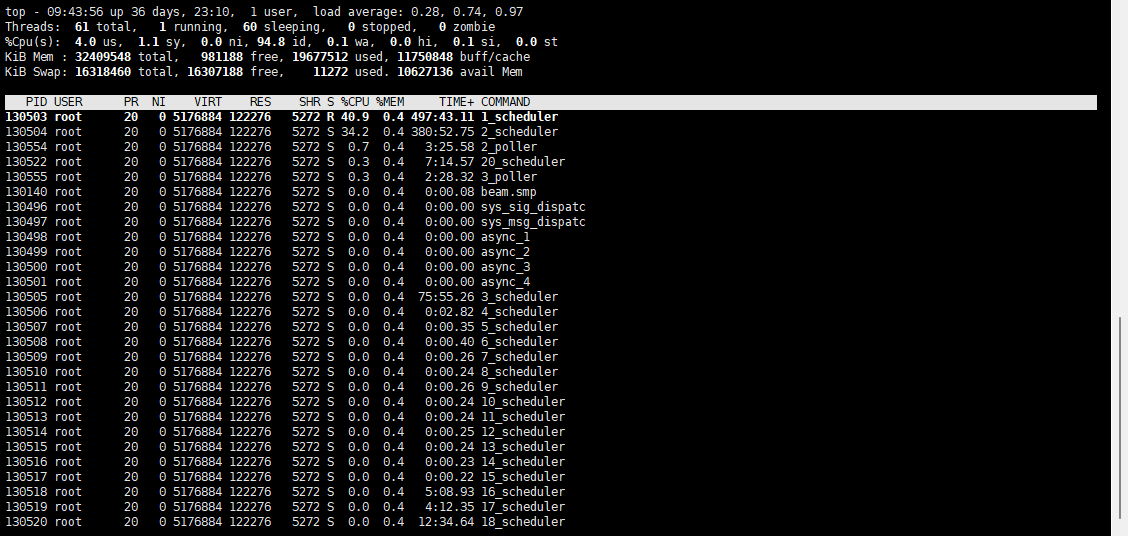
emqx运行大概1-2天后会出现beam.smp进程CPU占用超100%情况,会导致消息延迟,目前也就接入了几个测试设备,emqx做了桥接kafka,修改过桥接代码,如下图


beam.smp CPU超100%后重启emqx无效,kill掉进程后恢复正常,但是再运行1-2天又会出现CPU占用过高…
配置文件及日志
无
emqx运行大概1-2天后会出现beam.smp进程CPU占用超100%情况,会导致消息延迟,目前也就接入了几个测试设备,emqx做了桥接kafka,修改过桥接代码,如下图
beam.smp CPU超100%后重启emqx无效,kill掉进程后恢复正常,但是再运行1-2天又会出现CPU占用过高…
无
看起来是用了社区的kafka插件?
如果有 CPU 占用更高的话,可以试试看 erlang 的调试 CPU 的方式 Erlang -- etop
大概是
./bin/emqx attach 到 emqx 的后台spawn(fun() -> etop:start([{interval, 5}, {sort, reductions}]) end). 开启 etop 并按CPU使用量排序etop:stop(). 退出 etop;再用 CTRL+d 退出 emqx 后台是社区的kafka插件,我是在出现占用过高的时候调试 还是在正常的情况下调试?
快要到了是最好的
解决了么?? 什么问题??
7-80% 左右上去比较好。。。
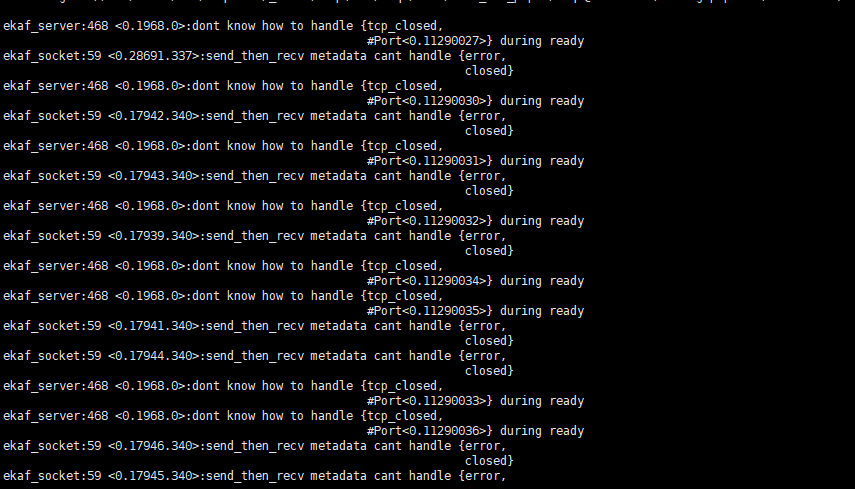
日志,看起来是这个 kafka 桥接的底层驱动已经很忙了,所以出现了很多错误日志打印
不好意思 回复完了,又出现了100% 我再按照你说的跟踪一下
现在看起来没什么压力,可以在持续观察下
ps:今天的 18% 指的是满值是 1600% 下的 18% (你这里看起来像是 16个核)
之前提到的的 100%,是值得占机器的 100% 还是 1600% 下的 100% ?
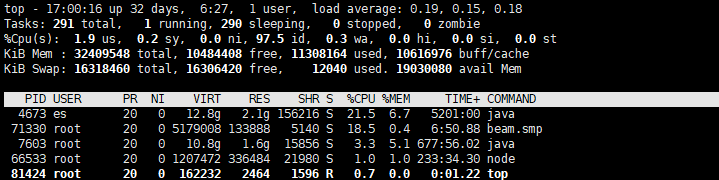
目前监测到CPU使用率在50 - 80 之间跳动,使用率是在1600%下的50 -80,以下是截图
top命令
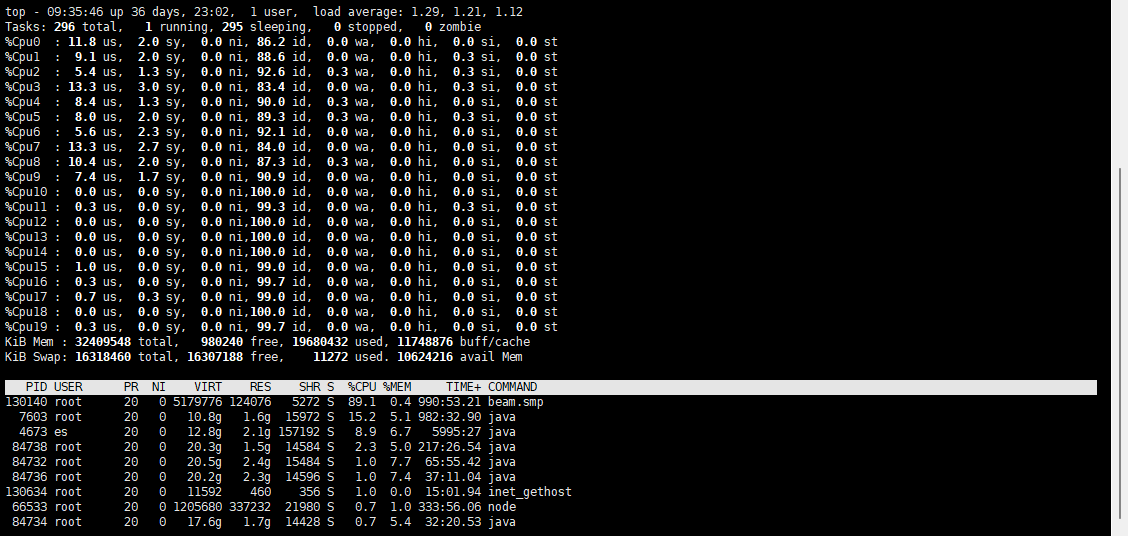
top -H -p 130140 进程查看
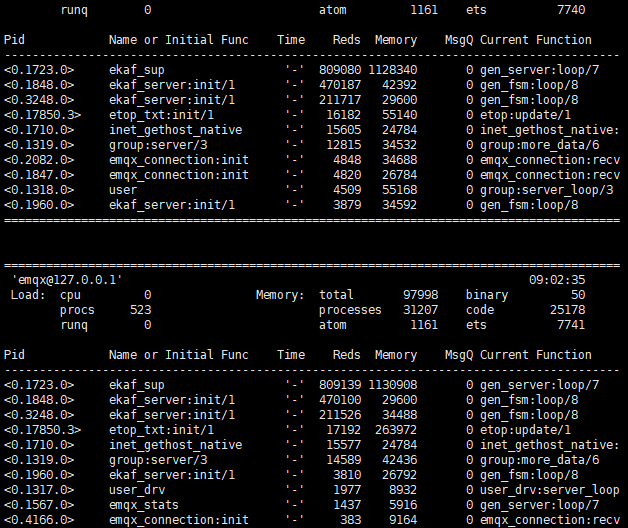
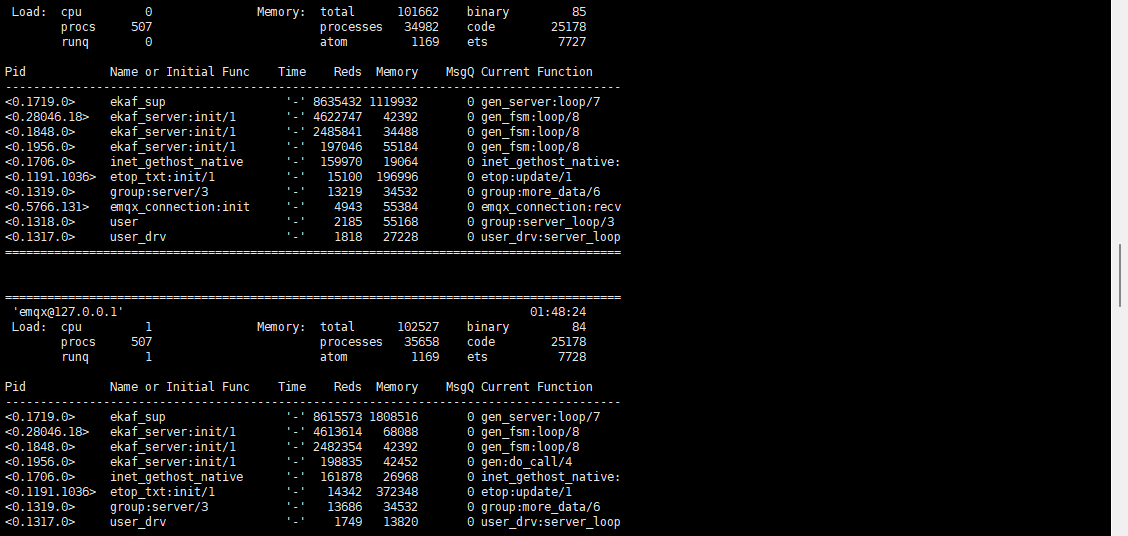
attach 截图
能从上图中分析出是什么原因导致的CPU使用率持续增长吗?
我看20核的CPU,最高应该可以到2000%,你这才89%,这应该还算正常吧。
不过再看上现的你连attach都连不上,看起来beam是忙得卡住了。
再看你的单个进程的top,scheduler只用了1和2,为什么其它的都没有用上。你是改了什么调优参数么。1. 把vm.args整个发出来看看。 2. 进入shell中查看一下CPU绑定结果:erlang:system_info(scheduler_bindings)., 其实就是看你的启动参数里面+A 是多少?一般都是设置+A CPU核数。
attach的etop图里面,只有3个ekaf_server,其中有2个很忙,你可以把ekaf的pool设置大一点。当前的请求量大约是多少?需要排除一下是请求量上来了,pool太小了,导致卡。
除了按reductionsr排序外,还可以接堆积的Q来排,看看是不是有消息卡住。
spawn(fun() -> etop:start([{interval, 5}, {sort, msg_q}]) end).
这个是tcp_closed 看起来像是kafka由于什么原因直接断开了连接,然后你用的库无法处理这种错。一直在打印。
如果这种错在日志文件中也是大量输出,也可能导致CPU高。
把emqx.log 日志打包一下,会好分析些。
感谢解答!
1.是20核CPU 但是beam.smp进程占用100%之后,emqx这边就会频繁的报错,attach也无法进入,消息也不会桥接到kafka。
3.emqx参数暂时未进行调整过,下面是vm.args 位置:emqx-rel/_build/emqx/rel/emqx/etc
######################################################################
## Erlang VM Args for EMQ X Broker
######################################################################
## NOTE:
##
## Arguments configured in this file might be overridden by configs from `emqx.conf`.
##
## Some basic VM arguments are to be configured in `emqx.conf`,
## such as `node.name` for `-name` and `node.cooke` for `-setcookie`.
## Sets the maximum number of simultaneously existing processes for this system.
+P 2097152
## Sets the maximum number of simultaneously existing ports for this system.
+Q 1048576
## Sets the maximum number of ETS tables
+e 262144
## Sets the maximum number of atoms the virtual machine can handle.
#+t 1048576
## Set the location of crash dumps
#-env ERL_CRASH_DUMP log/crash.dump
## Set how many times generational garbages collections can be done without
## forcing a fullsweep collection.
-env ERL_FULLSWEEP_AFTER 1000
## Heartbeat management; auto-restarts VM if it dies or becomes unresponsive
## (Disabled by default..use with caution!)
#-heart
## Specify the erlang distributed protocol.
## Can be one of: inet_tcp, inet6_tcp, inet_tls
#-proto_dist inet_tcp
## Specify SSL Options in the file if using SSL for Erlang Distribution.
## Used only when -proto_dist set to inet_tls
#-ssl_dist_optfile etc/ssl_dist.conf
## Specifies the net_kernel tick time in seconds.
## This is the approximate time a connected node may be unresponsive until
## it is considered down and thereby disconnected.
-kernel net_ticktime 120
## Sets the distribution buffer busy limit (dist_buf_busy_limit).
#+zdbbl 8192
## Sets default scheduler hint for port parallelism.
+spp true
## Sets the number of threads in async thread pool. Valid range is 0-1024.
## Increase the parameter if there are many simultaneous file I/O operations.
+A 4
## Sets the default heap size of processes to the size Size.
#+hms 233
## Sets the default binary virtual heap size of processes to the size Size.
#+hmbs 46422
## Sets the default maximum heap size of processes to the size Size.
## Defaults to 0, which means that no maximum heap size is used.
##For more information, see process_flag(max_heap_size, MaxHeapSize).
#+hmax 0
## Sets the default value for process flag message_queue_data. Defaults to on_heap.
#+hmqd on_heap | off_heap
## Sets the number of IO pollsets to use when polling for I/O.
#+IOp 1
## Sets the number of IO poll threads to use when polling for I/O.
## Increase this for the busy systems with many concurrent connection.
+IOt 4
## Sets the number of scheduler threads to create and scheduler threads to set online.
#+S 8:8
## Sets the number of dirty CPU scheduler threads to create and dirty CPU scheduler threads to set online.
#+SDcpu 8:8
## Sets the number of dirty I/O scheduler threads to create.
+SDio 8
## Suggested stack size, in kilowords, for scheduler threads.
#+sss 32
## Suggested stack size, in kilowords, for dirty CPU scheduler threads.
#+sssdcpu 40
## Suggested stack size, in kilowords, for dirty IO scheduler threads.
#+sssdio 40
## Sets scheduler bind type.
## Can be one of: u, ns, ts, ps, s, nnts, nnps, tnnps, db
#+sbt db
## Sets a user-defined CPU topology.
#+sct L0-3c0-3p0N0:L4-7c0-3p1N1
## Sets the mapping of warning messages for error_logger
#+W w
## Sets time warp mode: no_time_warp | single_time_warp | multi_time_warp
#+C no_time_warp
## Prevents loading information about source filenames and line numbers.
#+L
## Specifies how long time (in milliseconds) to spend shutting down the system.
## See: http://erlang.org/doc/man/erl.html
-shutdown_time 30000
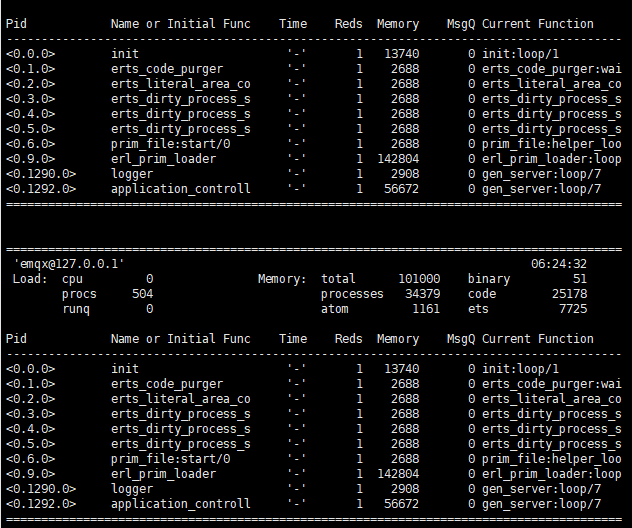
您说的查看CPU绑定结果是在attach中执行:erlang:system_info(scheduler_bindings).
如果是,那CPU绑定结果如下,应该是都未绑定吧

针对于我的服务环境,我需要将vm.args中 +A 4 改成 +A 20吗? 还需要调整什么参数吗?或者有什么调优方案吗?
4.当前的请求量很小,前端现在就两个采集网关,大概一分钟也就不到20条消息。
ekaf的pool该在哪里调整呢?
spawn(fun() → etop:start([{interval, 5}, {sort, msg_q}]) end).
还有一点就是emqx重启之后beam.smp进程CPU占用也就10%以内,请求量不变的情况下这个占用会随着时间慢慢的增长,最后到100%+ 后就开始报错了
你只用了+A 4 !!!把他调成+A 20, 再加一个
然后再 +sbt db(这个参数可以先不加)
请求量这么小,绝对是你用的ekaf有问题。。。
你得自己找找他的问题,
如何改pool,你也得自己找找。
不过还是推荐换个库,那个库都7-8年不更新了。:
https://github.com/kafka4beam/brod ,用这个啊。这个超好用。
好的,十分感谢 我更换下kafka的桥接组件试试。这个 组件支持emqx-rel v4.2.14吗?
另外您说的 +A 4 改成20 和添加 +sbt db 这两个参数还有别的参数吗?
其它的参数不用改。改了库你什么问题都没了。
好的 谢谢 我改下试试