root
1
您正在使用的 emqx 版本信息、操作系统类型。【关键】
emqx-5.7.2-el7-amd64.rpm
centos7
提供 emqx 的日志。【关键】
emqx配置客户端认证和授权使用HTTP服务,配置的url是nginx代理地址,ngnix代理了多个http后端服务用于高可用
系统之前运行是正常的吗?问题发生时做过什么操作?【关键】
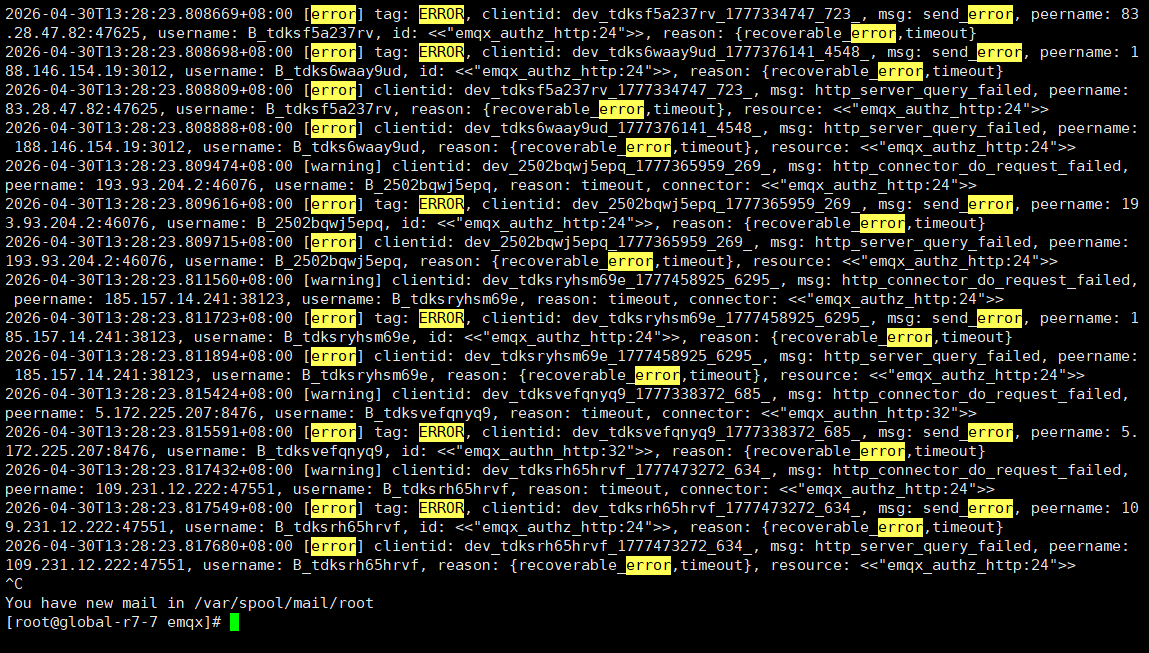
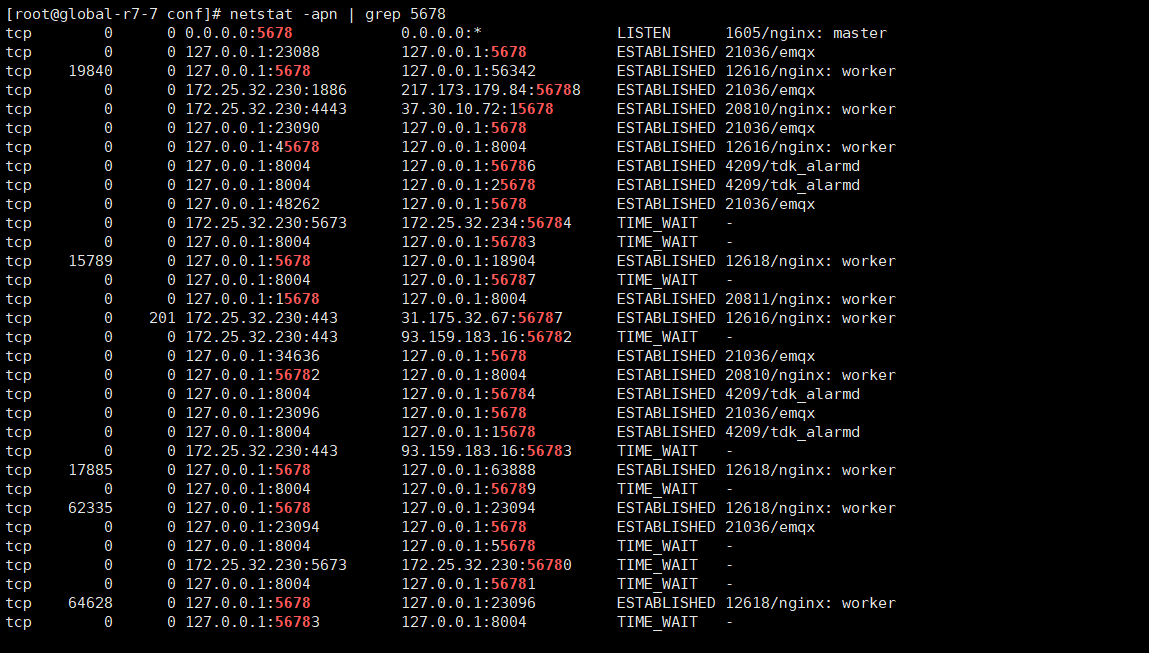
大量设备重连时出现的问题,emqx日志一直打印报错,设备在线数上不去;http后端服务日志是正常的在处理请求;观察到eqmx连nginx的连接的recv-q值比较大
把配置HTTP服务的url改成直接连服务,不通过nginx代理后恢复
尝试用什么方法调查过问题,目前得到的信息和结论。
怀疑是nginx代理、HTTP连接池、管道、超时配置造成的
想要咨询下是否建议使用nginx代理认证和授权的HTTP服务,还有连接池、管道、超时建议怎么去配置
这个现象基本就是认证/授权 HTTP 链路在代理层排队后触发超时,不是认证逻辑本身坏了。你这边“直连后恢复 + EMQX 到 Nginx 的 recv-q 变大”已经很能说明问题。
可以继续用 Nginx 做高可用,但先把参数收敛到“低排队、低管道、明确超时”:
- 先把 EMQX 的 HTTP 管道降到 1(等价先关闭 pipelining),不要用默认 100。
- 把认证器和授权器的连接池调大(先从 32 或 64 起步),避免重连风暴时队列堆积。
- request timeout / connect timeout 按后端 P99 延迟来配,不要让 Nginx 或后端超时小于 EMQX。
- 认证和授权如果共用一个 upstream,建议拆成两个 upstream,避免互相抢连接。
EMQX 5.7 文档里这几个参数就在 Dashboard 的高级设置:连接池大小、连接超时、HTTP 管道、请求超时。HTTP 认证默认连接池是 8,HTTP 管道默认 100,在“大量设备同时重连”场景里通常偏激进。
Nginx 侧建议至少确认:
proxy_http_version 1.1proxy_set_header Connection ""- upstream
keepalive 已开启
proxy_connect_timeout、proxy_read_timeout、proxy_send_timeout 与后端处理时延匹配
再补 3 组信息来 :
:
- EMQX 报
recoverable_error,timeout 的完整文本日志(贴文本,不要截图)。
- Nginx access log 里同一时段的
upstream_response_time、status 分布。
- 你当前认证器/授权器的 4 个参数值:
pool_size、enable_pipelining、connect_timeout、request_timeout。