集群情况,一个 core 节点,两个 repl 节点,k8s部署,core和repl分开在两个workload部署
其中有一个 repl 节点 (下称A节点) 之前宕机过一次,emqx_mria_lag 值变为 -8, 当时发帖询问过,message_queue_len和replayq_len为0的情况不需要人为干预,emqx_mria_server_mql基本也维持在0, 当时咨询得到的答复是,后期 repl 节点会自动 bootstrap+追平,不过后面没有额外的人为操作,lag值一直维持在-8,其他指标也没变化过,也没有追平
前几天 core 节点因为云厂商的问题宕机过一次,宕机约 10-15min,宕机后,A节点的emqx_delivery_dropped_queue_full 值从0变为11, emqx_mria_lag 从 -8 变为-7865
用 emqx eval 'mria_rlog:status().' 的输出结果是(已做脱敏处理):
#{role => replicant,backend => rlog,shards_down => [],
shard_stats =>
#{'$mria_meta_shard' =>
#{message_queue_len => 0,state => normal,
upstream =>
'emqx-aaaaaaa@emqx-ev-xxxx-yyyyy.svc.cluster.local',
bootstrap_num_keys => 3,bootstrap_time => 115,lag => 0,
last_imported_trans => 28,replayq_len => 0},
emqx_common_shard =>
#{message_queue_len => 0,state => normal,
upstream =>
'emqx-aaaaaaa@emqx-ev-xxxx-yyyyy.svc.cluster.local',
bootstrap_num_keys => 7,bootstrap_time => 90,lag => 0,
last_imported_trans => 2,replayq_len => 0},
emqx_cm_shard =>
#{message_queue_len => 0,state => normal,
upstream =>
'emqx-aaaaaaa@emqx-ev-xxxx-yyyyy.svc.cluster.local',
bootstrap_num_keys => 23,bootstrap_time => 120,lag => -4105,
last_imported_trans => 3629233,replayq_len => 0},
emqx_exclusive_shard =>
#{message_queue_len => 0,state => normal,
upstream =>
'emqx-aaaaaaa@emqx-ev-xxxx-yyyyy.svc.cluster.local',
bootstrap_num_keys => 1,bootstrap_time => 3,lag => 0,
last_imported_trans => 0,replayq_len => 0},
route_shard =>
#{message_queue_len => 0,state => normal,
upstream =>
'emqx-aaaaaaa@emqx-ev-xxxx-yyyyy.svc.cluster.local',
bootstrap_num_keys => 5,bootstrap_time => 54,lag => -248,
last_imported_trans => 3304603,replayq_len => 0},
emqx_shared_sub_shard =>
#{message_queue_len => 0,state => normal,
upstream =>
'emqx-aaaaaaa@emqx-ev-xxxx-yyyyy.svc.cluster.local',
bootstrap_num_keys => 1,bootstrap_time => 3,lag => 0,
last_imported_trans => 769,replayq_len => 0},
emqx_cluster_rpc_shard =>
#{message_queue_len => 0,state => normal,
upstream =>
'emqx-aaaaaaa@emqx-ev-xxxx-yyyyy.svc.cluster.local',
bootstrap_num_keys => 3,bootstrap_time => 5,lag => 0,
last_imported_trans => 3,replayq_len => 0},
emqx_authn_shard =>
#{message_queue_len => 0,state => normal,
upstream =>
'emqx-aaaaaaa@emqx-ev-xxxx-yyyyy.svc.cluster.local',
bootstrap_num_keys => 3,bootstrap_time => 6,lag => 0,
last_imported_trans => 1,replayq_len => 0},
emqx_acl_sharded =>
#{message_queue_len => 0,state => normal,
upstream =>
'emqx-aaaaaaa@emqx-ev-xxxx-yyyyy.svc.cluster.local',
bootstrap_num_keys => 1,bootstrap_time => 3,lag => 0,
last_imported_trans => 0,replayq_len => 0},
emqx_dashboard_shard =>
#{message_queue_len => 0,state => normal,
upstream =>
'emqx-aaaaaaa@emqx-ev-xxxx-yyyyy.svc.cluster.local',
bootstrap_num_keys => 3,bootstrap_time => 6,lag => 0,
last_imported_trans => 1,replayq_len => 0},
emqx_retainer_shard =>
#{message_queue_len => 0,state => normal,
upstream =>
'emqx-aaaaaaa@emqx-ev-xxxx-yyyyy.svc.cluster.local',
bootstrap_num_keys => 6,bootstrap_time => 10,lag => -9,
last_imported_trans => 325735,replayq_len => 0},
emqx_psk_shard =>
#{message_queue_len => 0,state => normal,
upstream =>
'emqx-aaaaaaa@emqx-ev-xxxx-yyyyy.svc.cluster.local',
bootstrap_num_keys => 1,bootstrap_time => 3,lag => 0,
last_imported_trans => 0,replayq_len => 0},
emqx_telemetry_shard =>
#{message_queue_len => 0,state => normal,
upstream =>
'emqx-aaaaaaa@emqx-ev-xxxx-yyyyy.svc.cluster.local',
bootstrap_num_keys => 2,bootstrap_time => 3,lag => 0,
last_imported_trans => 1,replayq_len => 0}},
shards_in_sync =>
['$mria_meta_shard',emqx_acl_sharded,emqx_authn_shard,
emqx_cluster_rpc_shard,emqx_cm_shard,emqx_common_shard,
emqx_dashboard_shard,emqx_exclusive_shard,emqx_psk_shard,
emqx_retainer_shard,emqx_shared_sub_shard,emqx_telemetry_shard,
route_shard]}
截至发稿前,另一个repl节点也出现了 emqx_delivery_dropped_queue_full 突增的情况,从 0 升至 95,看了一下监控,中间有大约半小时没有消息接收,也在这半小时里出现丢弃消息数剧增
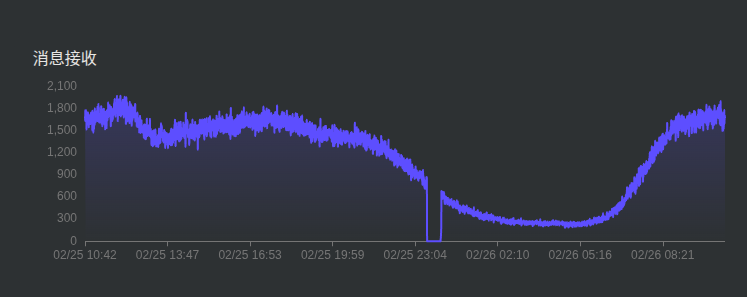
看了下目前业务上的一些订阅,有部分已使用共享订阅,当前最大消息队列长度为 1k,当前消息匹配速率:发布和接收速率大概在100条/秒 以内
现在有几个概念想理清楚,
- emqx_delivery_dropped_queue_full 这个值是一个历史结果值还是指当前的队列满丢弃数,这个值能否通过人为操作降为 0,
- 针对这种情况,有没有什么人为操作能恢复节点滞后性、队列满丢弃的现象