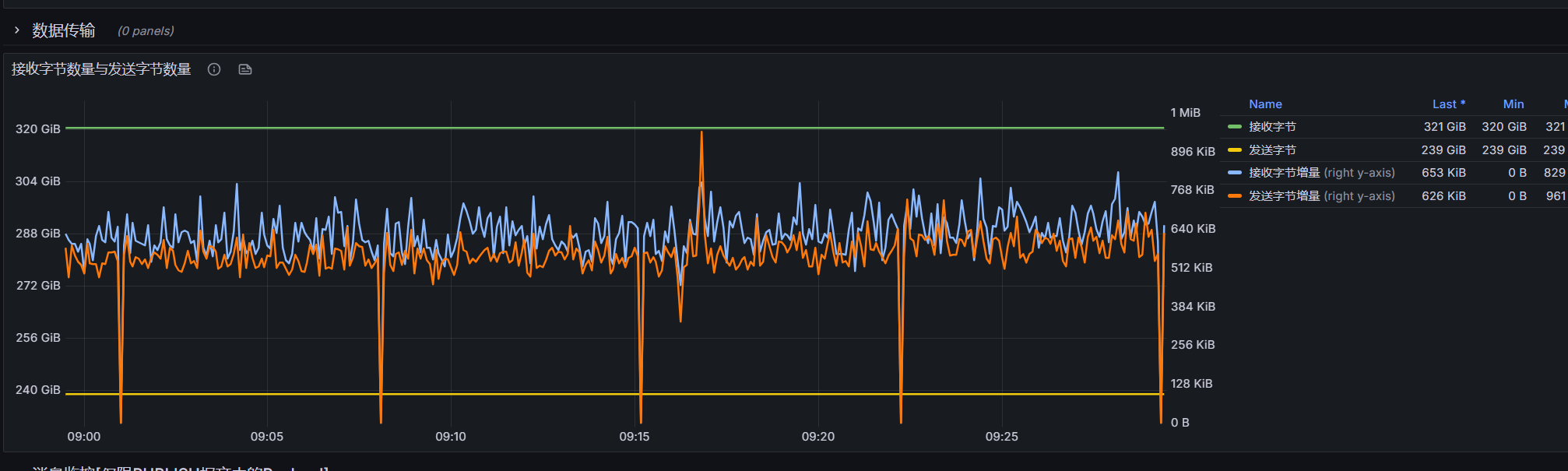
我们在用Prometheus+Grafana分析时,发现间隔6-7分钟会出现一次接收报文消息为0的情况,怀疑是否是fullGC的缘故? 我们参数调整是node.global_gc_interval = 3m
emqx_ctl recon node_stats的执行结果为
node_stats.zip (1.8 KB)
如果是fullGC的话,emqx的Prometheus的上报频率用的是5s一次,那就意味着fullGC5秒时长,这就太长了,帮忙分析一下是什么问题导致的
我们在用Prometheus+Grafana分析时,发现间隔6-7分钟会出现一次接收报文消息为0的情况,怀疑是否是fullGC的缘故? 我们参数调整是node.global_gc_interval = 3m
如果是fullGC的话,emqx的Prometheus的上报频率用的是5s一次,那就意味着fullGC5秒时长,这就太长了,帮忙分析一下是什么问题导致的
我觉得不可能,
不过你可以直接设置 node.global_gc_interval = disabled ,这样就可以验证有没有影响了(我觉得从你的 node stats来看,是不可能 GC 这么久的,资源消耗都不高)。
同时:如果没有内存压力,建议直接把这个值长期设置disabled
我们自己压测时发现这个参数在 CPU 达到 80% 后,再开启这个参数,会造成反作用。
还不如不开。所以在下面这个 PR 里面已经把默认值改成 disabled 了。
你的 node_stats看起来非常的正常,接收报文消息为 0,有可能是因为 prometheus 收集间隔设置过短了,你设置长一点。比如 30 秒。试一试效果。
但是我们的消息基本上都是不间断的,不可能有一个点不接收消息;
而且这个消息接收为0还有点规律,基本上6-7分钟出现一次
我们是集群部署的,4个节点都有这种现象,只是说出现的时间点并不是一致
这个接收消息为0,如果是线程挂起的话,那就意味着有那么几秒收不到消息,gc应该也不会这么久,但是还是无法定位问题,采集频率拉长那只是看起来没有问题罢了。
有什么指令可以看gc的记录吗? 根据我现在掌握的信息,还无法定位fullGC的次数以及耗时,这个版本是4.2版本的是否有其他的方式可以获取到更多的信息?
没有。
4.2 已经于2022-04-12过了给维护周期了,有条件赶快升级吧: