环境
- EMQX 版本: v5.10.0,v5.10.1
- 操作系统版本:CentOS Linux release 7.9.2009
重现此问题的步骤
- ExHook 能正常处理
- ExHook 调用的服务在更新或者异常断开一段时间(大概5分钟以上)
- ExHook 不会重连无法开关,也无法删除,调用的服务即使恢复正常也不会重试。
预期行为
ExHook 能够重连
实际行为
ExHook 完全无法控制,除非重启整个 EMQX
这个在 5.8 以前的版本没有出现过
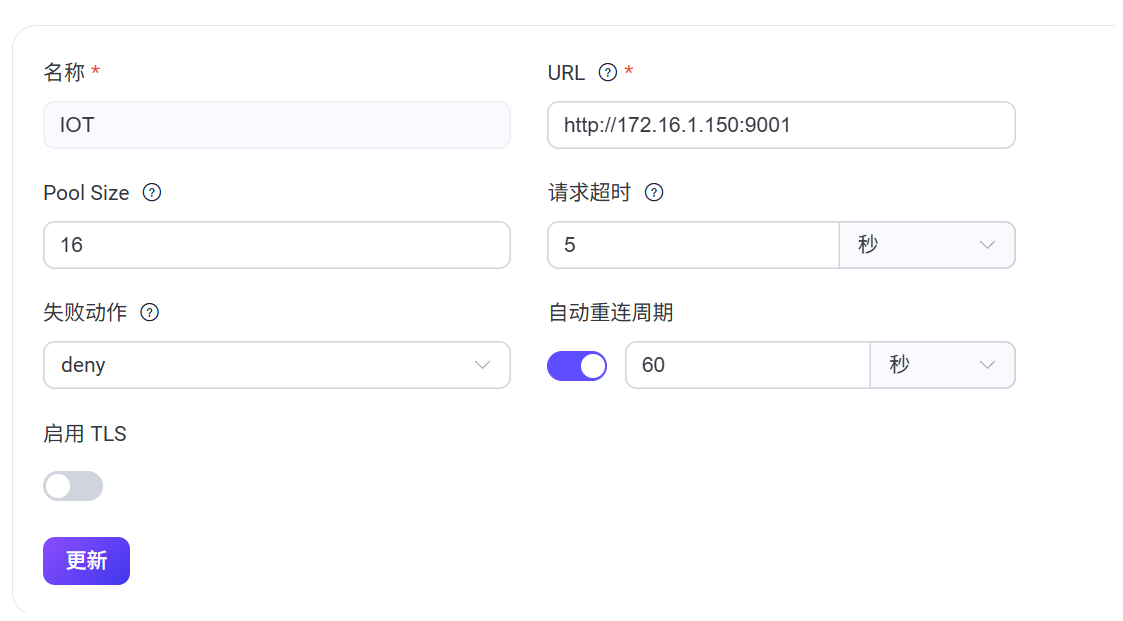
请求信息
请求内容:
{“auto_reconnect”:“”,“enable”:false,“failed_action”:“deny”,“name”:“IOT”,“pool_size”:16,“request_timeout”:“5s”,“ssl”:{“ciphers”:,“depth”:10,“enable”:false,“hibernate_after”:“5s”,“log_level”:“notice”,“middlebox_comp_mode”:true,“reuse_sessions”:true,“secure_renegotiate”:true,“verify”:“verify_peer”,“versions”:[“tlsv1.3”,“tlsv1.2”]},“url”:“http://172.16.1.150:9001”}
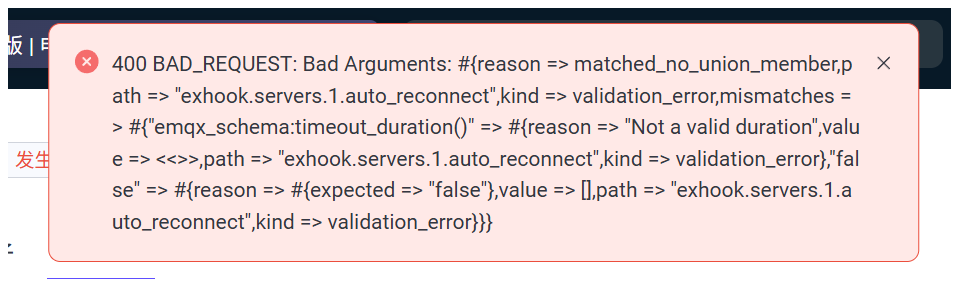
响应消息:
Bad Arguments: #{reason => matched_no_union_member,path => “exhook.servers.1.auto_reconnect”,kind => validation_error,mismatches => #{“emqx_schema:timeout_duration()” => #{reason => “Not a valid duration”,value => <<>>,path => “exhook.servers.1.auto_reconnect”,kind => validation_error},“false” => #{reason => #{expected => “false”},value => ,path => “exhook.servers.1.auto_reconnect”,kind => validation_error}}}