我的emqx集群部署在云服务器的K8s平台上,使用emqx-operator-controller-manager管理。
以下是我的yaml文件
apiVersion: apps.emqx.io/v2beta1
kind: EMQX
metadata:
name: emqx
namespace: real
spec:
image: emqx:5.5.0
coreTemplate:
spec:
replicas: 3
volumeClaimTemplates:
storageClassName: standard
resources:
requests:
storage: 10Gi
accessModes:
- ReadWriteOnce
extraVolumes:
- name: ssl-self-sign
secret:
secretName: ssl-self-sign
extraVolumeMounts:
- name: ssl-self-sign
mountPath: /mounted/cert
replicantTemplate:
spec:
replicas: 3
extraVolumes:
- name: ssl-self-sign
secret:
secretName: ssl-self-sign
extraVolumeMounts:
- name: ssl-self-sign
mountPath: /mounted/cert
dashboardServiceTemplate:
spec:
type: NodePort
ports:
- name: dashboard
nodePort: 30811
port: 18083
protocol: TCP
targetPort: 18083
listenersServiceTemplate:
spec:
type: NodePort
ports:
- name: ssl-default
nodePort: 32349
port: 8883
protocol: TCP
targetPort: 8883
- name: tcp-default
nodePort: 32350
port: 1883
protocol: TCP
targetPort: 1883
- name: ws-default
nodePort: 32347
port: 8083
protocol: TCP
targetPort: 8083
- name: wss-default
nodePort: 32348
port: 8084
protocol: TCP
targetPort: 8084
- name: tcp-program
nodePort: 32351
port: 1993
protocol: TCP
targetPort: 1993
我在EMQ的监控告警中看到了多条类似下面的告警信息
emqx_authn_http:6269953 resource down: closed emqx@10.244.13.254 系统 2025-04-17 01:28:22
reason: resource_down
resource_id: emqx_authn_http:11126819
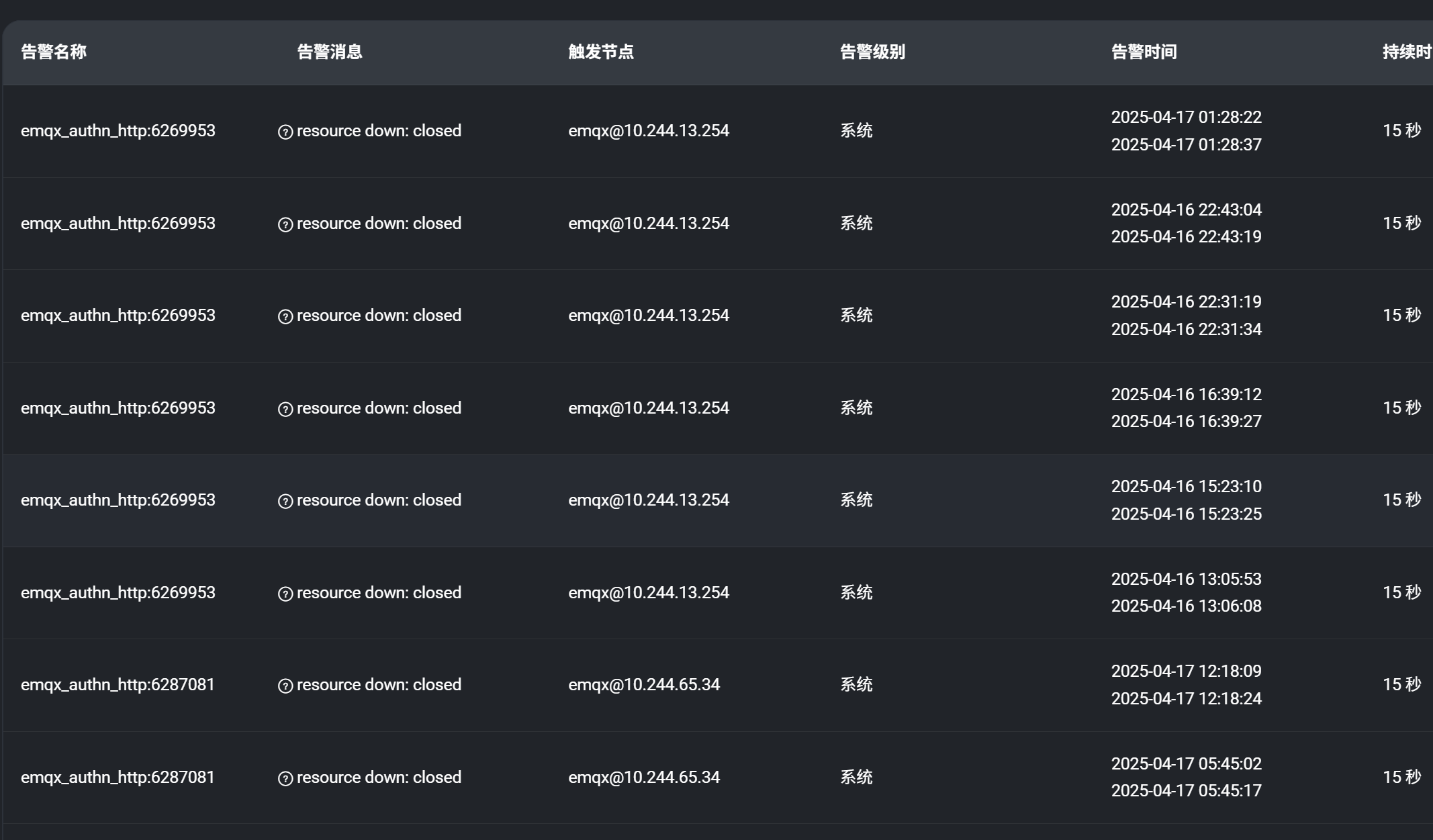
想知道这是什么原因造成的