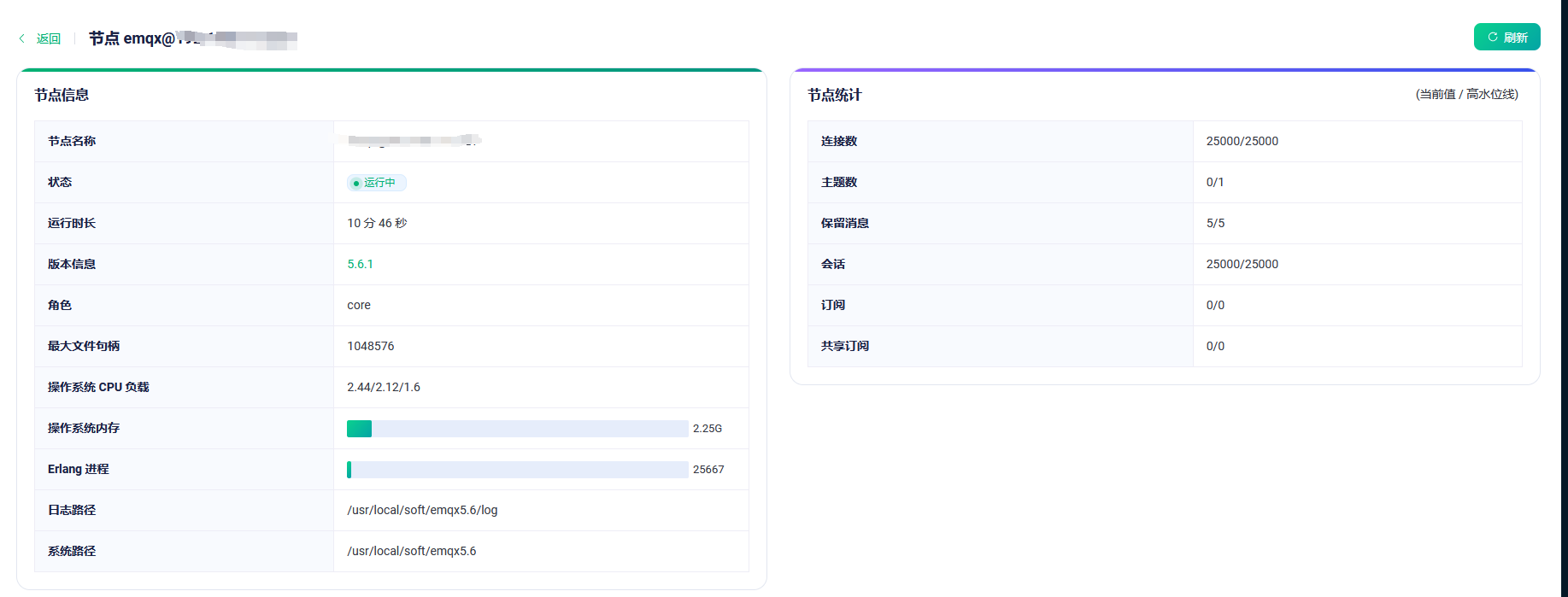
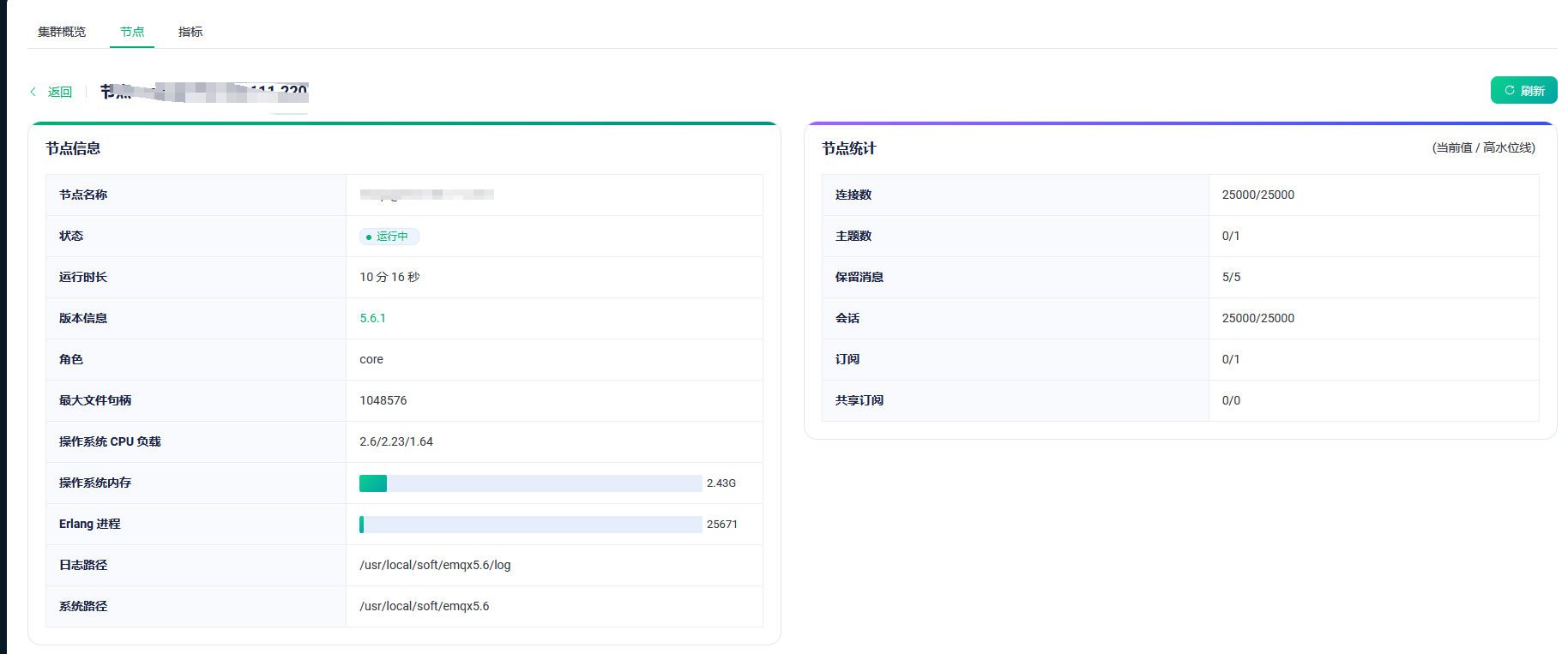
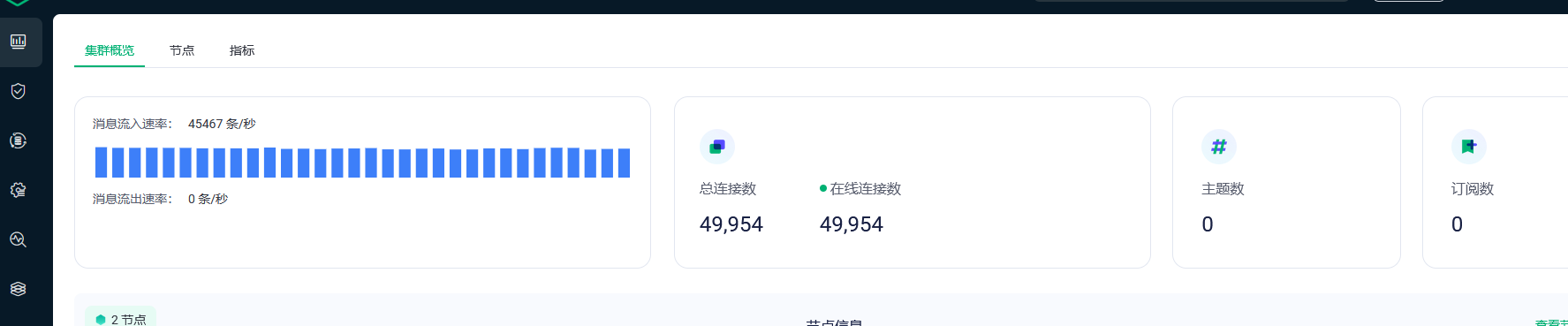
服务器确认都已按文档系统调优 | EMQX 5.6 文档
做了系统相关的调优并且都是千兆网卡
a服务器收发流量流量在260M左右,b服务器也是,c服务器620M左右
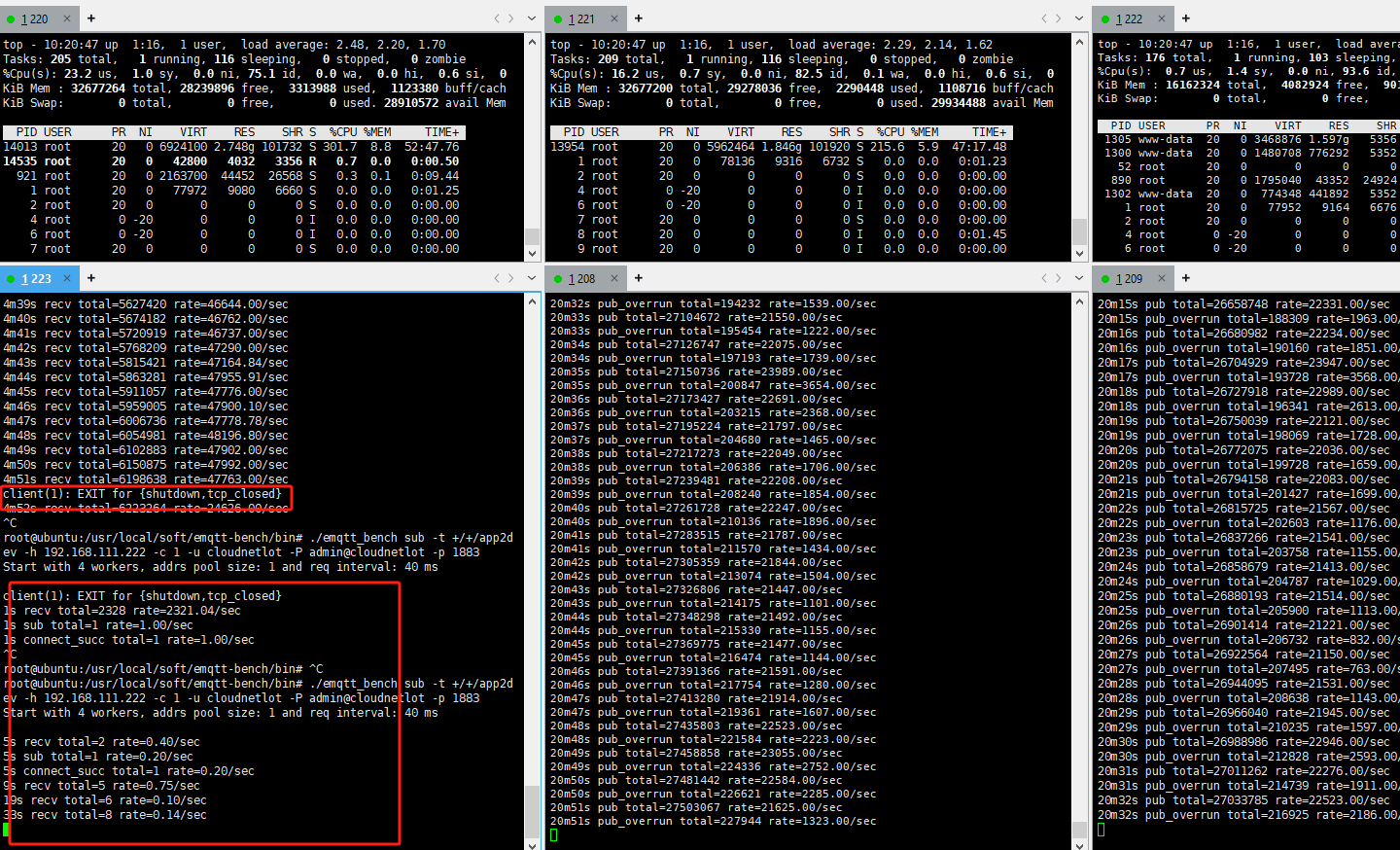
通过其他两台压力机进行emqtt_bench pub发送消息打压,一个订阅
主要问题
1.订阅段会报client(1): EXIT for {shutdown,tcp_closed},订阅失败,
表现形式:客户端在测试20分钟之后,报错掉线验证
2.服务器有预警信息
预警信息1:
connection congested: #{memory => 37176,message_queue_len => 2,pid => <<“<0.5494659.0>”>>,reductions => 15447,send_pend =>
1082,peername => <<“192.168.111.***:48204”>>,sockname => <<“192.168.111.***1883”>>,buffer => 4096,high_msgq_watermark => 8192,high_watermark =>
1048576,recbuf => 374400,sndbuf => 87040,recv_cnt => 2,recv_oct => 100,send_cnt => 16,send_oct => 29528,username => <<“cloudnetlot”>>,clientid =>
<<“ubuntu_bench_sub_4111510873_1”>>,socktype => tcp,conn_state => connected,proto_name => <<“MQTT”>>,proto_ver => 5,connected_at => 1736935626420}
预警信息2:
connection congested: #{memory => 26736,message_queue_len => 0,pid => <<“<0.475604.0>”>>,reductions => 17601,send_pend => 4708,peername =>
<<“192.168.111.222:29094”>>,sockname => <<“192.168.111.221:1883”>>,buffer => 4096,high_msgq_watermark => 8192,high_watermark =>
1048576,recbuf => 374400,sndbuf => 87040,recv_cnt => 2,recv_oct => 100,send_cnt => 21,send_oct => 32672,username => <<“cloudnetlot”>>,
clientid => <<“ubuntu_bench_sub_3912537162_1”>>,socktype => tcp,proto_name => <<“MQTT”>>,
proto_ver => 5,connected_at => 1736935844606,conn_state => connected}
3.压力机客户端pub_overrun是否有影响
12m59s pub_overrun total=270196 rate=535.00/sec
pub_overrun这个是否对测试有影响
服务器日志如下:
2025-01-15T17:54:36.289483+08:00 [warning] msg: cluster_config_fetch_failures, peer_nodes: [‘emqx@192.168.111.221’], self_node: ‘emqx@192.168.111.220’, booting_nodes: [{error,#{node => ‘emqx@192.168.111.221’,wall_clock => {1035,67},msg => “init_conf_load_not_done”,release => “v5.6.1”}}], failed_nodes:
2025-01-15T17:54:36.346483+08:00 [warning] msg: cluster_routing_schema_discovery_failed, reason: Could not determine configured routing storage schema in peer nodes., responses: [{‘emqx@192.168.111.221’,unknown,starting}]
2025-01-15T17:56:34.150021+08:00 [warning] msg: alarm_is_activated, message: <<“connection congested: #{memory => 265712,message_queue_len => 4,pid => <<"<0.3775.0>">>,reductions => 39610836,send_pend => 6600,peername => <<"192.168.111.229:16544">>,sockname => <<"192.168.111.220:1883">>,buffer => 4096,high_msgq_watermark => 8192,high_watermark => 1048576,recbuf => 374400,sndbuf => 104448,recv_cnt => 2,recv_oct => 100,send_cnt => 76770,send_oct => 85444920,username => <<"c”…>>, name: <<“conn_congestion/ubuntu_bench_sub_4101390393_1/cloudnetlot”>>
2025-01-15T17:57:34.152107+08:00 [warning] msg: alarm_is_deactivated, name: <<“conn_congestion/ubuntu_bench_sub_4101390393_1/cloudnetlot”>>
2025-01-15T17:59:12.117038+08:00 [warning] msg: alarm_is_activated, message: <<“connection congested: #{memory => 71320,message_queue_len => 3,pid => <<"<0.3775.0>">>,reductions => 828709294,send_pend => 278,peername => <<"192.168.111.229:16544">>,sockname => <<"192.168.111.220:1883">>,buffer => 4096,high_msgq_watermark => 8192,high_watermark => 1048576,recbuf => 374400,sndbuf => 530944,recv_cnt => 2,recv_oct => 100,send_cnt => 1426559,send_oct => 2028045682,username => <”…>>, name: <<“conn_congestion/ubuntu_bench_sub_4101390393_1/cloudnetlot”>>
2025-01-15T18:00:13.242285+08:00 [warning] msg: alarm_is_deactivated, name: <<“conn_congestion/ubuntu_bench_sub_4101390393_1/cloudnetlot”>>
2025-01-15T18:03:18.252518+08:00 [warning] msg: alarm_is_activated, message: <<“connection congested: #{memory => 124232,message_queue_len => 1,pid => <<"<0.3775.0>">>,reductions => 4048964552,send_pend => 1854,peername => <<"192.168.111.229:16544">>,sockname => <<"192.168.111.220:1883">>,buffer => 4096,high_msgq_watermark => 8192,high_watermark => 1048576,recbuf => 374400,sndbuf => 1114112,recv_cnt => 3,recv_oct => 102,send_cnt => 6668693,send_oct => 10328508682,username”…>>, name: <<“conn_congestion/ubuntu_bench_sub_4101390393_1/cloudnetlot”>>
2025-01-15T18:03:37.343987+08:00 [warning] msg: alarm_is_deactivated, name: <<“conn_congestion/ubuntu_bench_sub_4101390393_1/cloudnetlot”>>
2025-01-15T18:03:37.344144+08:00 [error] supervisor: {esockd_connection_sup,<0.3775.0>}, errorContext: connection_shutdown, reason: #{max => 1000,reason => mailbox_overflow,value => 2485}, offender: [{pid,<0.3775.0>},{name,connection},{mfargs,{emqx_connection,start_link,[#{listener => {tcp,default},limiter => undefined,enable_authn => true,zone => default}]}}]
2025-01-15T18:07:06.422807+08:00 [warning] msg: alarm_is_activated, message: <<“connection congested: #{memory => 37176,message_queue_len => 2,pid => <<"<0.5494659.0>">>,reductions => 15447,send_pend => 1082,peername => <<"192.168.111.222:48204">>,sockname => <<"192.168.111.220:1883">>,buffer => 4096,high_msgq_watermark => 8192,high_watermark => 1048576,recbuf => 374400,sndbuf => 87040,recv_cnt => 2,recv_oct => 100,send_cnt => 16,send_oct => 29528,username => <<"cloudnetl”…>>, name: <<“conn_congestion/ubuntu_bench_sub_4111510873_1/cloudnetlot”>>
2025-01-15T18:07:22.250722+08:00 [error] Process: <0.5494659.0> on node ‘emqx@192.168.111.220’, Context: maximum heap size reached, Max Heap Size: 6291456, Total Heap Size: 168654149, Kill: true, Error Logger: true, Message Queue Len: 0, GC Info: [{old_heap_block_size,66222786},{heap_block_size,58170533},{mbuf_size,44260858},{recent_size,973510},{stack_size,18},{old_heap_size,0},{heap_size,2984850},{bin_vheap_size,4864222},{bin_vheap_block_size,9235836},{bin_old_vheap_size,0},{bin_old_vheap_block_size,3527924}]