emqx运行了1个半小时,没有任何客户端连接的情况下,cpu占用周期性冲到一个多核,收发数据也一直有。这情况怎么解决?
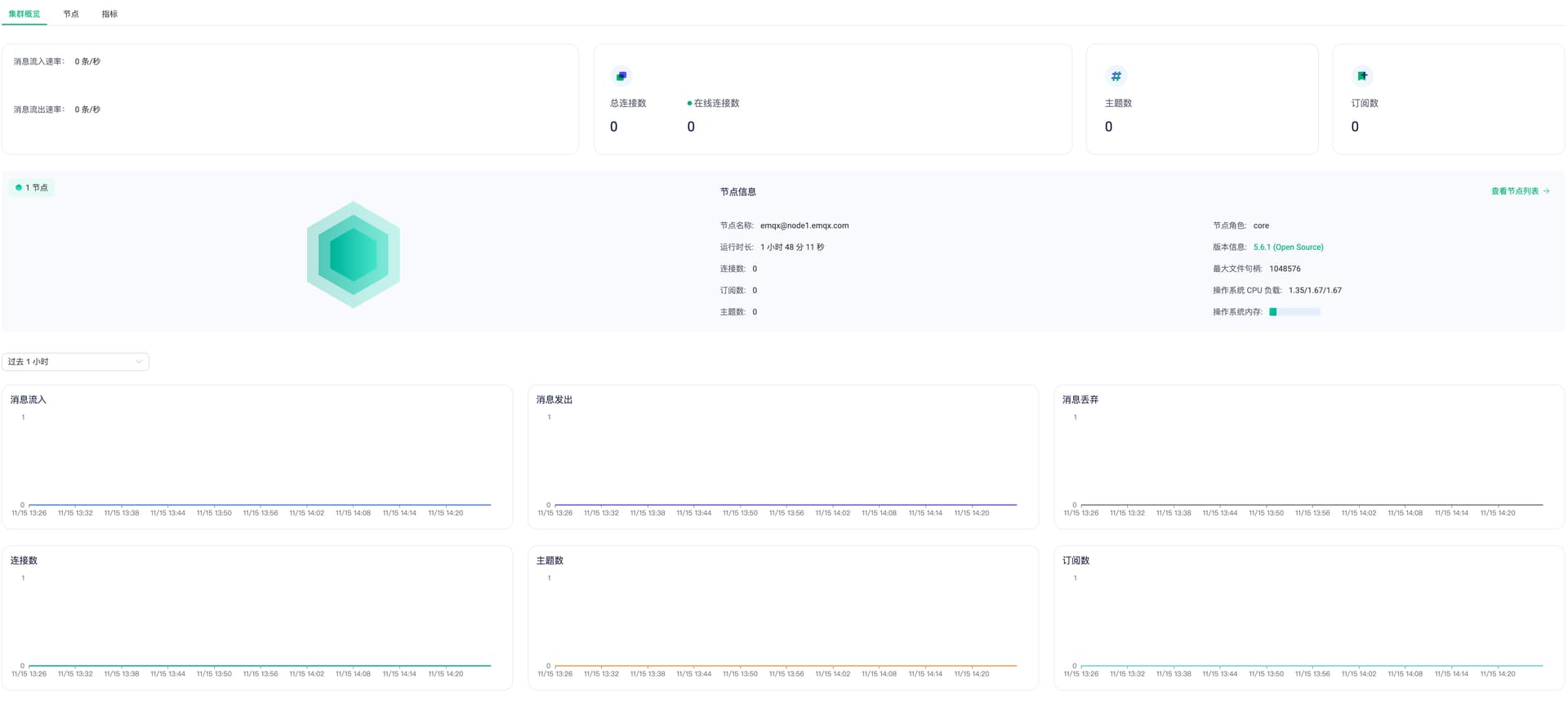
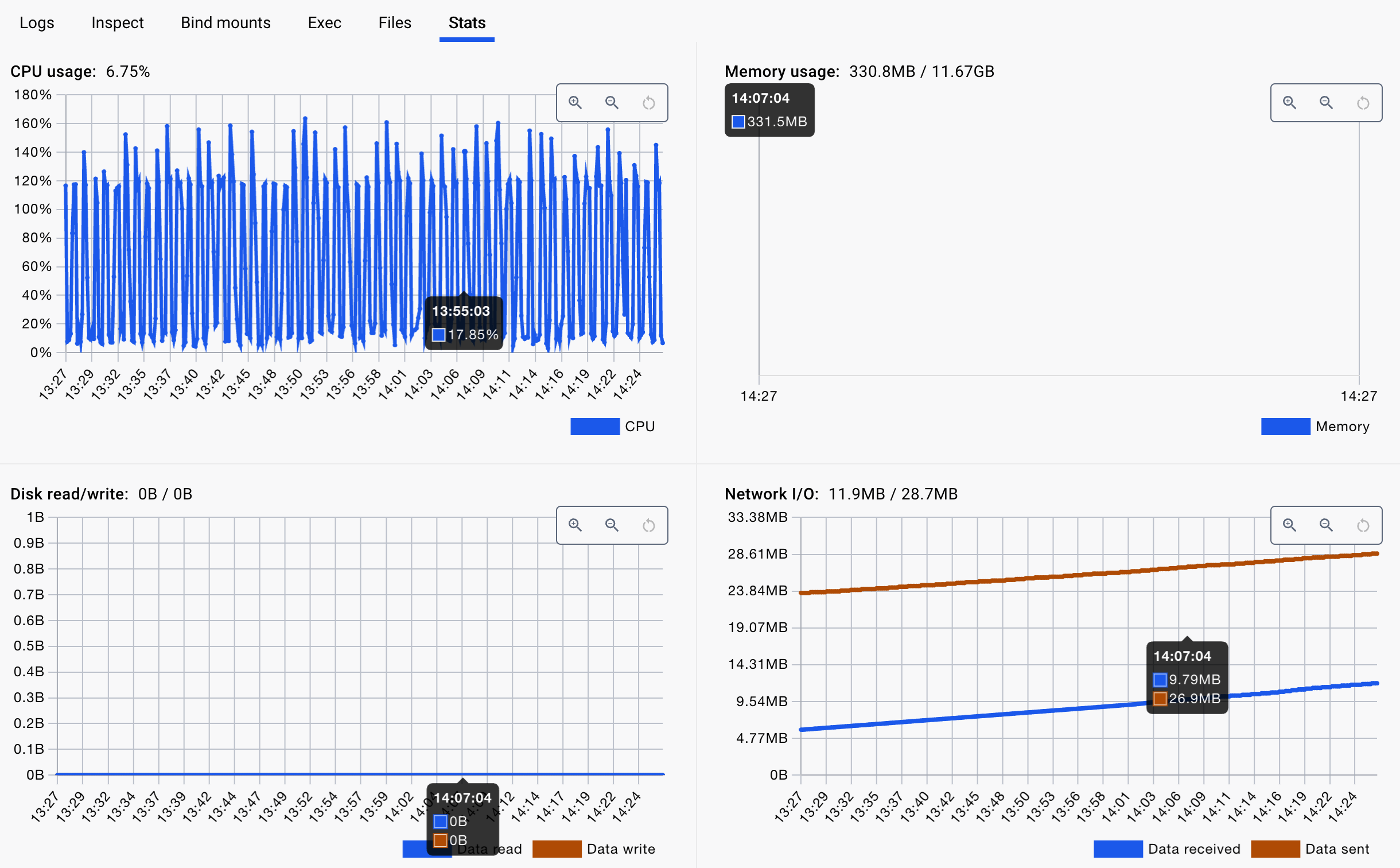
这个看起来像是 prometheus 定时拉取,5.8.2 后默认会关掉那些耗CPU 的指标了
不升级版本的情况,能关闭吗?
能通过配置来控制吗?
配置控制有 bug,所有就没告诉你,升级版本就能配置控制
我升级到5.8.2,再观察下。另外,升级后的监控页面没了。
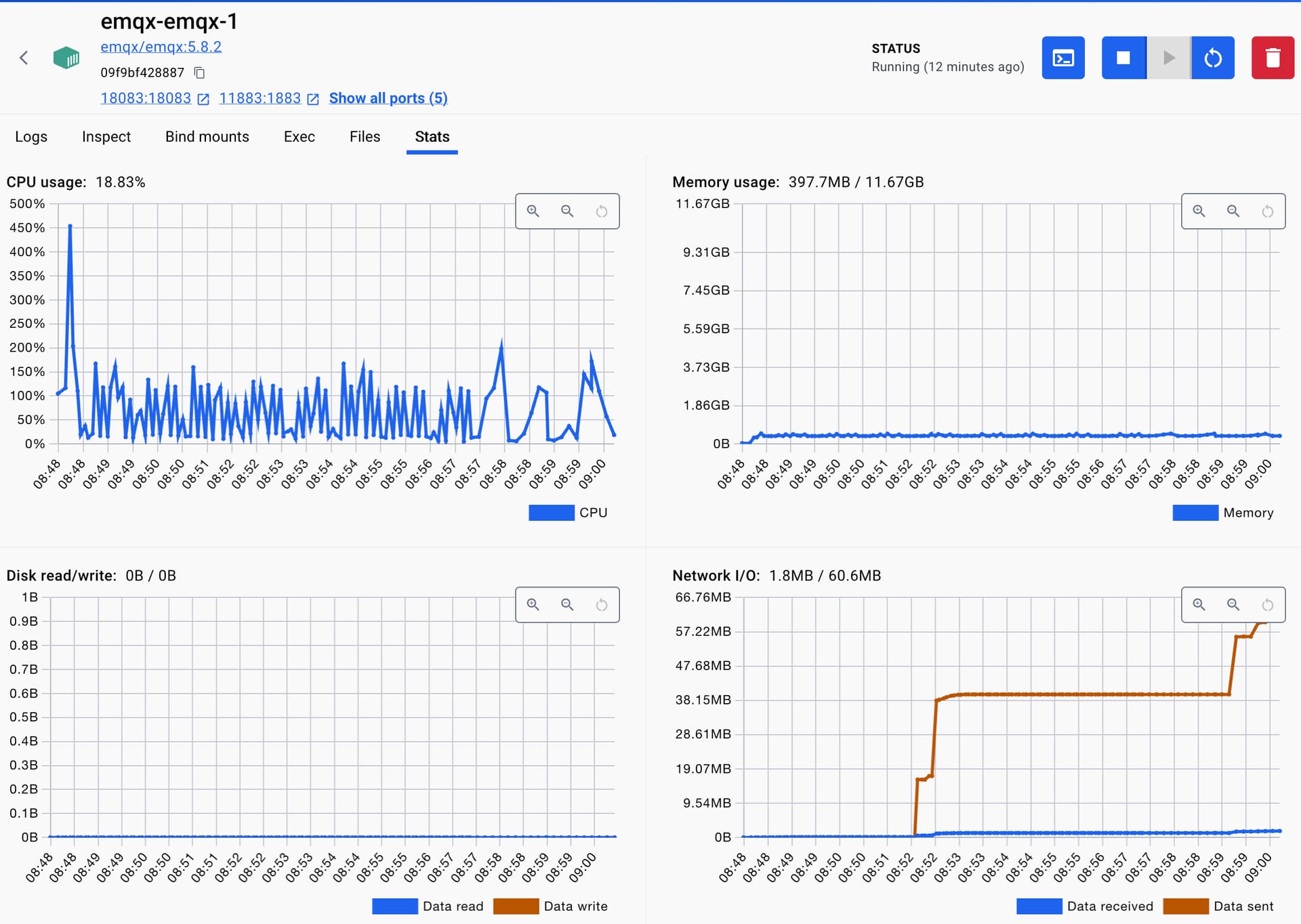
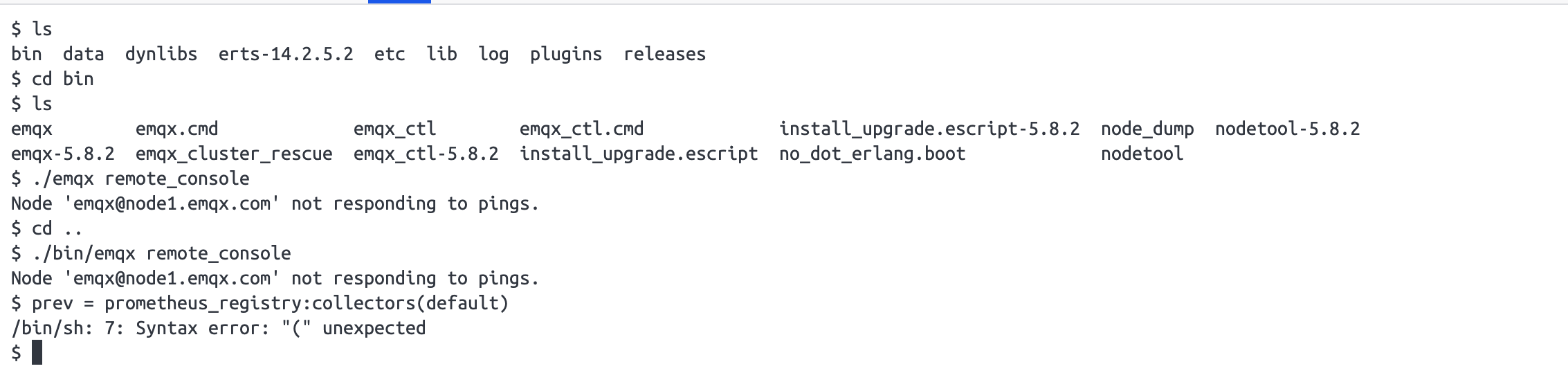
你这个节点应该是没有完全安装成功。
你 ping 一下看看,应该都 ping 不通的。
./bin/emqx ping

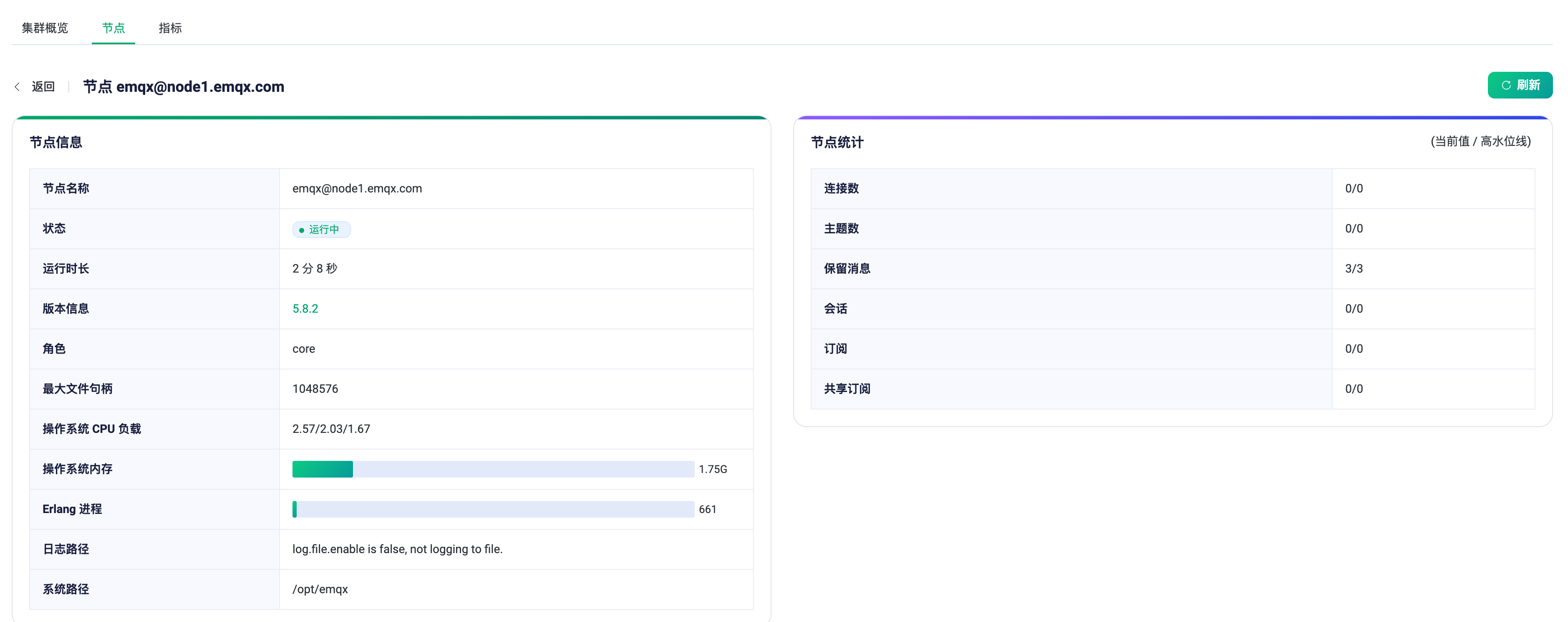
看起来是 hostname 没设置。你的 node1.emqx.com 指向哪里了?
PS:而且你的日志过少了,只有控制台的启动日志。其它的文件日志呢,是没开启还是?
麻烦问一下:使用的操作系统是什么,启动命令是怎么样的?
5.6是能运行的
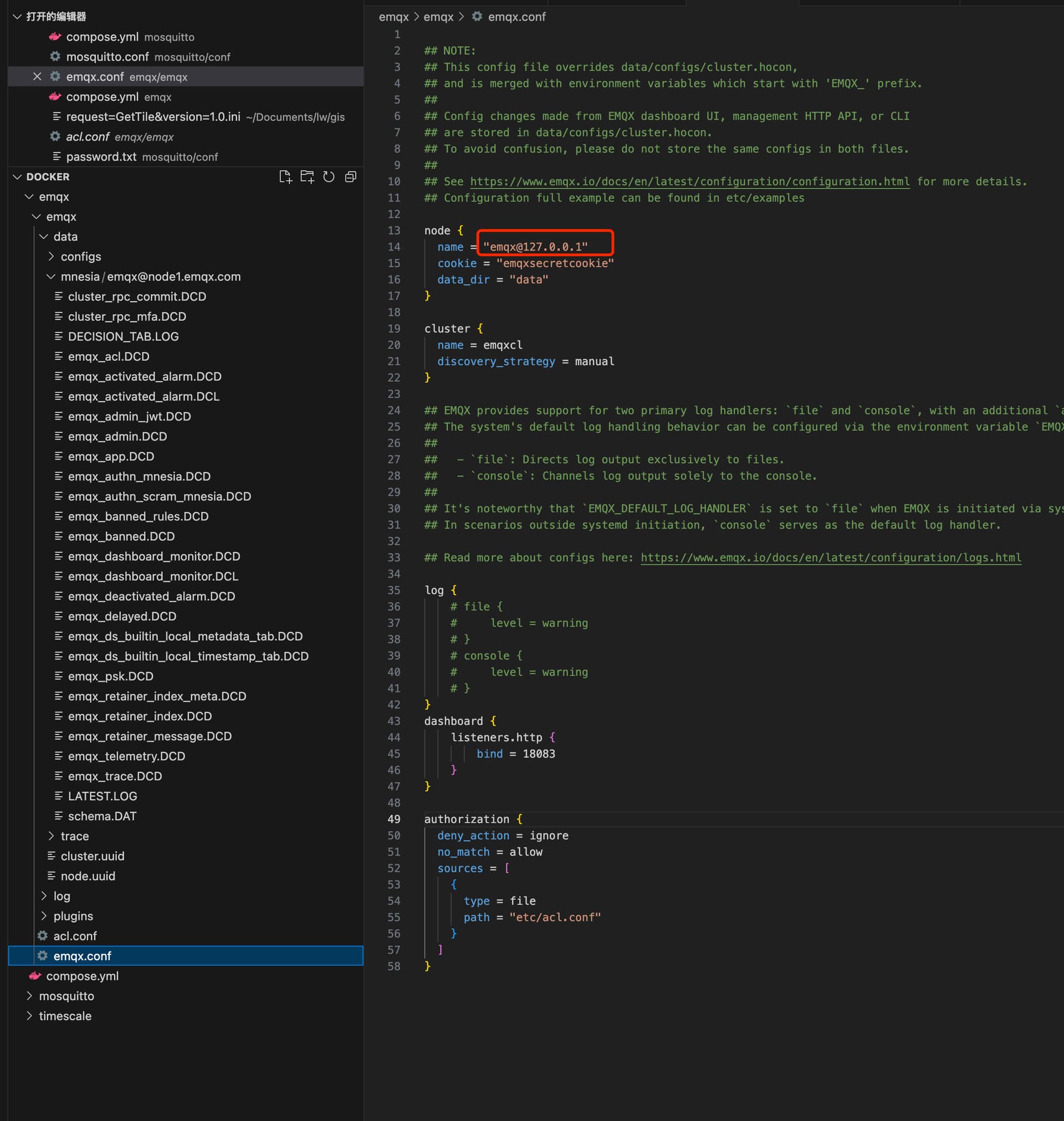
需要我提供哪些log?我应该没开什么log ![]()
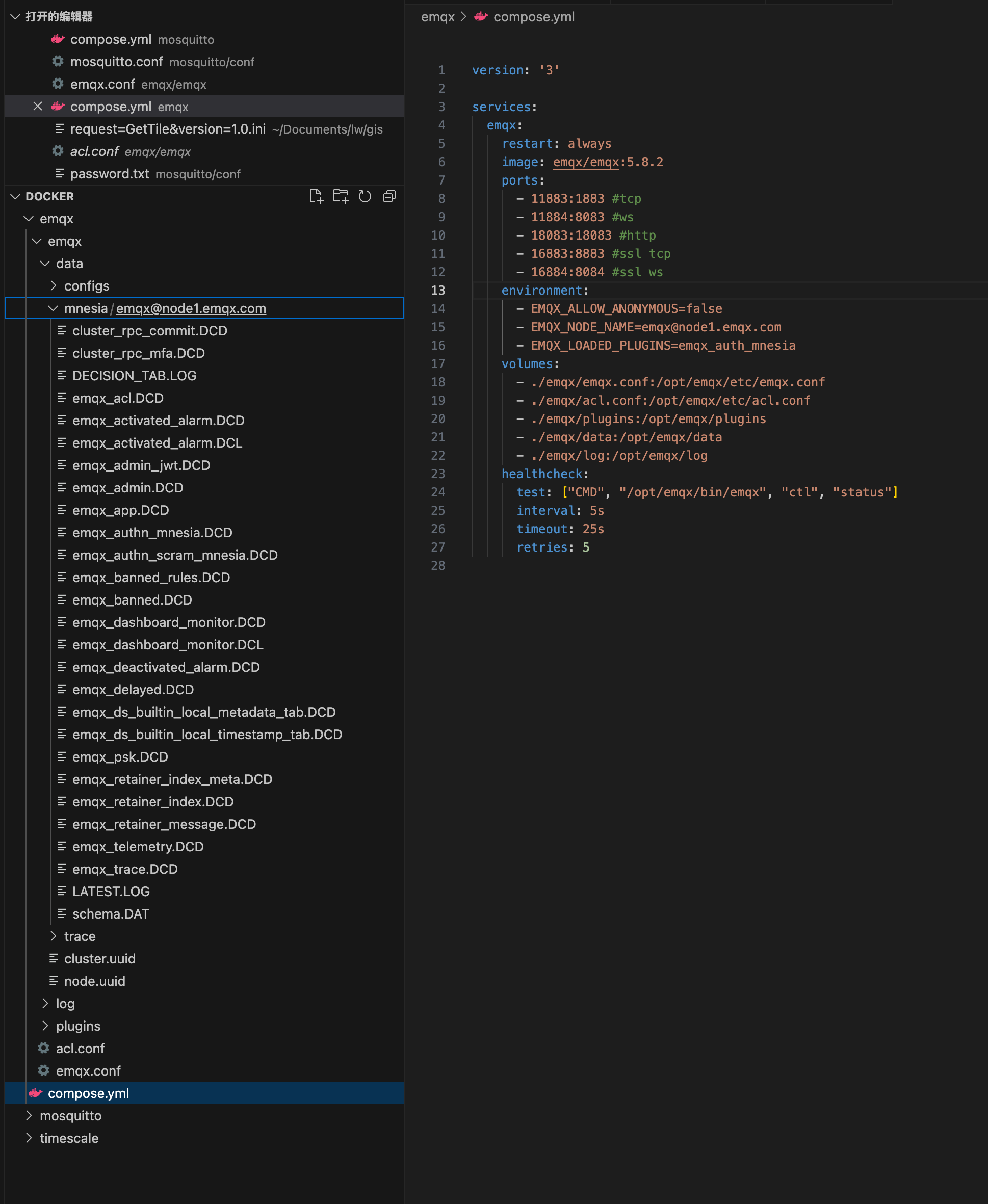
有点怀疑你的 docker compose 里面有个 healthcheck (因为那个命令 ping 不通,完全不能用)一直不成功,5*5=25 秒不成功就一直在重启原因导致的 CPU 升高吧。
compose.yaml 有点问题:
- 你得在加上 hostname:
restart: on-failure
image: emqx/emqx:5.8.2
container_name: node1.emqx.com
- envionment 里面只有 EMQX_NODE__NAME 是有效的,其它 2 个应该都是 4.x 的,对 5.x 没有用,可以删掉。
- 如果改了上面 2 点启动成功后,
且使用./bin/emqx ctl status 有正确的返回结果(没有 ping 不通)后,CPU 还是会周期变高,
为了排除 healthcheck 的影响,可以先把 healthchek 的内容全注释掉,看是否能正常,这样排除一下是不是这个 healthcheck 的影响。
非常感谢您的帮助。
好像真的是这个healthCheck造成的,我按照你说的改了之后,关了healthCheck之后才好了。但是这个/opt/emqx/bin/emqx ctl status是能正常返回结果的,我也试了/opt/emqx/bin/emqx ping,也会有周期性的飙升。
有没有其他能用于healthCheck的指令?
命令行执行一下就会 CPU 高一点是一个已知的问题,目前没什么好的解决方法,优先级比较低,下周周会会看看能不能优化一下。
替代方案一(我不确定 docker 里面有没有内置 curl,如果已内置,就可以直接用这个 api 代替):
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:18083/status"]
interval: 5s
timeout: 30s
retries: 5
替代方案二:
你可以自己写个 PS 命令脚本,判断只要emqx进程是不是活着
不过我个人觉得,其实你可以直接删掉这个 healthcheck,因为如果这个进程不在了,他这个 container 就直接退出了的。没什么大的必要。
1 个赞